„V „pandách“ môžeme ľahko prečítať textový súbor pomocou metódy „pandy“. „Pandy“ nám poskytujú možnosť čítať textový súbor. „Pandas“ poskytuje rôzne vstavané metódy na čítanie textového súboru. Budeme diskutovať o všetkých metódach v tomto návode spolu so všetkými parametrami a podrobne ich vysvetlíme. Tiež budeme čítať textový súbor v „pandách“ pomocou metód „pandy“ v našich kódoch tu.
Metódy čítania textového súboru v „pandách“
V „pandách“ máme tri metódy, ktoré nám pomáhajú pri čítaní textového súboru. Tiež sme tu urobili niekoľko príkladov, v ktorých čítame textový súbor. Metódy, ktoré „pandy“ poskytujú, sú popísané nižšie:
-
- Použitím metódy pd.read_csv().
- Použitím metódy pd.read_table().
- Použitím metódy pd.read_fwf().
Teraz vysvetľujeme syntax všetkých týchto metód a tiež podrobne diskutujeme o parametroch všetkých metód v tomto návode.
Syntax read_csv()
pd.read_csv ( ‘názov súboru.txt’, sept =' ', hlavička = Žiadne, mená = [ “Stĺpec_name1”, “Stĺpec_name2, “Stĺpec_name2”, ………….. ] )
Pri tejto metóde najskôr pridáme názov textového súboru, ktorého údaje chceme čítať a je to prvý parameter tejto metódy. Potom umiestnime „sep“, čo je oddeľovač v tejto metóde, a umiestnime sem medzeru ako znak, takže bude medzeru považovať za oddeľovač. Potom máme parameter hlavičky a použije sa hodnota tohto parametra „Žiadne“, takže vytvorí predvolenú hlavičku a ak tento parameter nepridáme, bude brať do úvahy prvý riadok textového súboru ako hlavička. Do parametra „names“ môžeme pridať názvy stĺpcov, ktoré musíme pridať ako hlavičku.
Syntax funkcie read_table()
pd.read_table ( 'názov súboru.txt' , oddeľovač = ' ' )
Pri tejto metóde uvádzame ako prvý parameter názov textového súboru. Keď do oddeľovača umiestnime „ “, ako oddeľovač sa použije znak medzery.
Syntax read_fwf()
pd.read_fwf ( 'názov súboru.txt' )
Táto metóda má iba jeden parameter, ktorým je názov textového súboru.
Teraz použijeme tieto metódy na čítanie textových súborov v kódoch „pandy“ a zobrazenie údajov textového súboru na termináli.
Príklad #01
Aplikácia „Spyder“ je tu, v ktorej sme urobili všetky tieto kódy, ktoré sú uvedené v tomto návode. Textový súbor, ktorého údaje chceme čítať, je zobrazený nižšie. Na čítanie tohto textového súboru v „pandách“ použijeme metódu „read_csv()“.
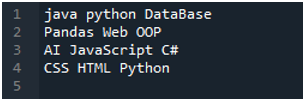
Najprv importujeme knižnicu „pandy“, pretože chceme použiť metódu „read_csv()“, a je to metóda „pandy“. K tejto metóde pristupujeme iba vtedy, keď sme importovali knižnicu „pandy“. Tu spomíname „pandy ako pd“, takže toto „pd“ je umiestnené s názvom metódy na jeho použitie. Potom tu vytvoríme premennú „df“, ktorá slúži na ukladanie údajov textového súboru po prečítaní. Sem umiestnime metódu „pd.read_csv()“, ktorá pomáha pri čítaní textového súboru a konverzii údajov textového súboru do DataFrame a ich ukladaní do premennej „df“.
Tu sme odovzdali názov súboru, ktorý je „myData.txt“, a potom použijeme „sep“ a tomuto „sep“ priradíme prázdny znak. Tento prázdny znak teda funguje ako oddeľovač v textovom súbore. Potom sme použili „print()“ nižšie, ktorý sa používa na tlač údajov textového súboru. Zobrazí údaje textového súboru vo forme DataFrame.
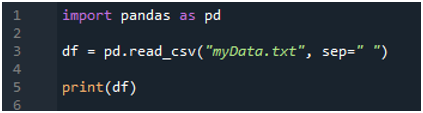
Na vykonanie tohto kódu musíme stlačiť „Shift+Enter“ a výstup sa vykreslí na termináli „Spyder“. Výsledok vyššie uvedeného kódu sa zobrazí na danej snímke obrazovky a môžete vidieť, že údaje textového súboru sú zobrazené ako DataFrame a prvý riadok nášho textového súboru je tu prezentovaný ako názvy stĺpcov tohto DataFrame. Tiež oddeľuje údaje, kde sa v textovom súbore nachádza znak medzery.
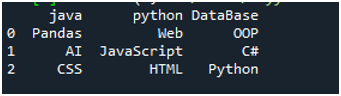
Príklad #02
Tu je zobrazený textový súbor, ktorý budeme čítať v tomto príklade, a opäť použijeme metódu „read_csv()“, ale s inými parametrami.
Používa sa metóda „pandy“ „pd.read_csv()“ a odovzdávame tu tri parametre. Najprv umiestnime názov súboru, ktorý je „Record.txt“. Druhý parameter je parameter „sep“ a priraďuje mu prázdny znak a potom máme tretí parameter, v ktorom nastavíme „header“ a upravíme ho na „None“, takže vytvorí predvolenú hlavičku DataFrame. keď spustíme tento kód. Toto všetko sme uložili do premennej “My_Record” a pridali “My_Record” aj do funkcie “print()” pre tlač.

Všetky dáta sú uložené v DataFrame a oddeľuje dáta tam, kde je medzera v dátach textového súboru. Tiež tu vytvoril predvolenú hlavičku DataFrame, pretože sme upravili parameter „header“ na „None“.
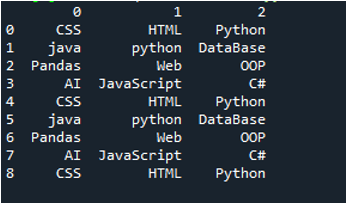
Príklad #03
Zobrazí sa textový súbor tohto príkladu a ešte raz použijeme metódu „read_csv()“ s upravenými parametrami.
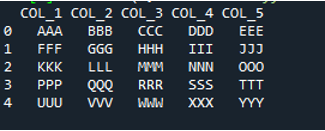
V tomto kóde sú štyri parametre odovzdané metóde „pandy“ „pd.read_csv()“. Názov textového súboru je prvým parametrom. Parameter „sep“ má v druhom parametri prázdny znak. Parameter „header“ je v treťom argumente nastavený na „None“ a ako štvrtý parameter sme nastavili „names“, ktoré sa objavia ako názvy stĺpcov DataFrame po prečítaní textového súboru a tieto názvy stĺpcov sú „COL_1, COL_2, COL_3, COL_4 a COL_5“. Všetky tieto informácie boli uložené v premennej „My_Record“ a „My_Record“ bol tiež pridaný do metódy „print()“, takže sa vytlačí na termináli.

Všetky informácie textového súboru sú tu vykreslené ako DataFrame a tiež oddeľuje údaje, do ktorých sú v textovom súbore pridané medzery. Podľa toho pridá aj názvy stĺpcov, ktoré sme pridali vyššie v kóde.
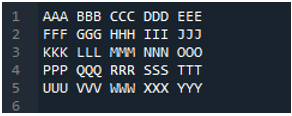
Príklad #04
Toto je textový súbor, ktorý v tomto príklade prečítame použitím inej metódy, metódy „pd.read_table()“.
Na čítanie textového súboru je tu pridaná metóda „pd.read_table()“ a pridávame „ABC.txt“, čo je názov textového súboru. Táto metóda pomáha pri čítaní textového súboru a tiež sme upravili parameter „oddeľovač“ na znak medzery, takže bude fungovať aj ako oddeľovač, ktorý sme vysvetlili vyššie. Potom sa všetky údaje textového súboru uložia do premennej „My_Data“ a tu sa aj vytlačia.

Počiatočný riadok nášho textového súboru je tu zobrazený ako názvy stĺpcov DataFrame a dáta textového súboru sú vytlačené ako DataFrame. Okrem toho oddeľuje údaje textového súboru, kde sa v ňom nachádza znak medzery.
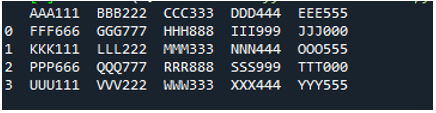
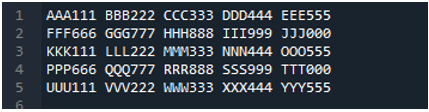
Príklad #05
Teraz textový súbor obsahuje údaje, ktoré sú zobrazené nižšie. Tentoraz použijeme „read_fwf()“ a ukážeme, ako vykresľuje dáta po prečítaní textového súboru.
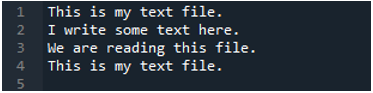
Ako vieme, táto metóda “read_fwf()” má iba jeden parameter, ktorým je názov súboru, ktorý chceme čítať. Sem pridáme „textfile.txt“, čo je názov nášho textového súboru a túto metódu pandas priradíme do premennej „File_Data“, ktorá bude uchovávať údaje tohto textového súboru. Potom zadáme „print(File_Data)“, takže vytlačí aj tieto údaje.

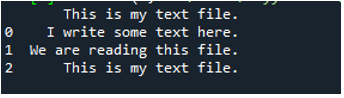
Tu sú zobrazené všetky údaje textového súboru. Neoddelil údaje, v ktorých sú prítomné medzery, pretože v tejto funkcii nie je žiadny parameter ako „Sep“ alebo „oddeľovač“.
Záver
Tento tutoriál vysvetľuje, ako čítať textový súbor v „pandách“ a aké metódy sa používajú na čítanie textového súboru v „pandách“. Diskutovali sme o všetkých metódach, ktoré nám pomáhajú pri čítaní textového súboru v „pandách“. V tomto návode sme preskúmali tri rôzne metódy „pandy“ na čítanie našich textových súborov v „pandách“. Tiež sme tu podrobne vysvetlili syntax všetkých metód, ako aj parametre všetkých metód a prečítali sme si veľa textových súborov použitím rôznych metód so všetkými možnými parametrami v tomto návode.