Umelá inteligencia je jednou z najrýchlejšie rastúcich technológií, ktoré využívajú algoritmy strojového učenia na trénovanie a testovanie modelov využívajúcich obrovské dáta. Dáta môžu byť uložené v rôznych formátoch, ale na vytváranie veľkých jazykových modelov pomocou LangChain je najpoužívanejším typom JSON. Tréningové a testovacie údaje musia byť jasné a úplné bez akýchkoľvek nejasností, aby model mohol efektívne fungovať.
Táto príručka bude demonštrovať proces používania pydantického analyzátora JSON v LangChain.
Ako používať analyzátor Pydantic (JSON) v LangChain?
Údaje JSON obsahujú textový formát údajov, ktoré je možné zhromažďovať prostredníctvom webového zoškrabovania a mnohých ďalších zdrojov, ako sú protokoly atď. Na overenie presnosti údajov používa LangChain pydantickú knižnicu z Pythonu na zjednodušenie procesu. Ak chcete použiť pydantický analyzátor JSON v LangChain, jednoducho si prejdite túto príručku:
Krok 1: Nainštalujte moduly
Ak chcete začať s procesom, jednoducho nainštalujte modul LangChain a použite jeho knižnice na používanie analyzátora v LangChain:
pip Inštalácia langchain
Teraz použite „ pip nainštalovať ” na získanie rámca OpenAI a využitie jeho prostriedkov:
pip Inštalácia openai
Po nainštalovaní modulov sa jednoducho pripojte k prostrediu OpenAI poskytnutím jeho API kľúča pomocou „ vy “ a „ getpass “knižnice:
importujte násimportovať getpass
os.environ [ 'OPENAI_API_KEY' ] = getpass.getpass ( 'OpenAI API Key:' )

Krok 2: Importujte knižnice
Pomocou modulu LangChain importujte potrebné knižnice, ktoré možno použiť na vytvorenie šablóny pre výzvu. Šablóna výzvy popisuje metódu kladenia otázok v prirodzenom jazyku, aby model mohol výzve efektívne porozumieť. Tiež importujte knižnice ako OpenAI a ChatOpenAI, aby ste vytvorili reťazce pomocou LLM na vytvorenie chatbota:
z langchain.prompts import (PromptTemplate,
ChatPromptTemplate,
HumanMessagePromptTemplate,
)
z langchain.llms importujte OpenAI
z langchain.chat_models importujte ChatOpenAI
Potom importujte pydantické knižnice, ako sú BaseModel, Field a validator, aby ste mohli použiť analyzátor JSON v LangChain:
z langchain.output_parsers importujte PydanticOutputParserz pydantického importu BaseModel, Field, validator
zadaním importovať zoznam
Krok 3: Vytvorenie modelu
Po získaní všetkých knižníc na používanie pydantického analyzátora JSON jednoducho získajte vopred navrhnutý testovaný model s metódou OpenAI():
názov_modelu = 'text-davinci-003'teplota = 0,0
model = OpenAI ( meno modela =názov_modelu, teplota = teplota )
Krok 4: Nakonfigurujte Actor BaseModel
Zostavte si ďalší model a získajte odpovede týkajúce sa hercov, ako sú ich mená a filmy, požiadaním o filmografiu herca:
herec triedy ( BaseModel ) :meno: str = Pole ( popis = 'Meno hlavného herca' )
film_names: Zoznam [ str ] = Pole ( popis = 'Filmy, v ktorých hral herec' )
herec_dotaz = 'Chcem vidieť filmografiu akéhokoľvek herca'
parser = PydaticOutputParser ( pydantický_objekt = Herec )
prompt = PromptTemplate (
šablóna = 'Odpovedzte na výzvu od používateľa. \n {format_instructions} \n {dopyt} \n ' ,
vstupné_premenné = [ 'dopyt' ] ,
čiastočné_premenné = { 'format_instructions' : parser.get_format_instructions ( ) } ,
)
Krok 5: Testovanie základného modelu
Jednoducho získajte výstup pomocou funkcie parse() s výstupnou premennou obsahujúcou výsledky vygenerované pre výzvu:
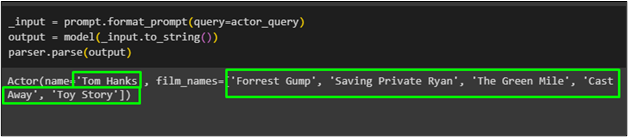
_input = prompt.format_prompt ( dopyt =dotaz_aktora )výstup = model ( _input.to_string ( ) )
parser.parse ( výkon )
Herec s názvom „ Tom Hanks ” so zoznamom jeho filmov bol získaný pomocou pydantickej funkcie z modelu:
To je všetko o použití pydantického analyzátora JSON v LangChain.
Záver
Ak chcete použiť pydantický analyzátor JSON v LangChain, jednoducho nainštalujte moduly LangChain a OpenAI a pripojte sa k ich zdrojom a knižniciam. Potom importujte knižnice ako OpenAI a pydantic, aby ste vytvorili základný model a overili údaje vo forme JSON. Po vytvorení základného modelu vykonajte funkciu parse() a vráti odpovede na výzvu. Tento príspevok demonštroval proces používania pydantického analyzátora JSON v LangChain.