Pandy patria medzi najpopulárnejšie nástroje, ktoré dnes vedci využívajú na analýzu tabuľkových údajov. Na zvládnutie tabuľkového obsahu ponúka rýchlejšie a efektívnejšie API. Kedykoľvek si počas analýzy prezeráme dátové rámce, Pandas automaticky nastaví rôzne správanie zobrazenia na predvolené hodnoty. Medzi tieto spôsoby zobrazenia patrí počet riadkov a stĺpcov, ktoré sa majú zobraziť, presnosť pohyblivých písmen v každom dátovom rámci, veľkosti stĺpcov atď. V závislosti od požiadaviek môže byť niekedy potrebné upraviť tieto predvolené hodnoty. Pandy majú rôzne prístupy na zmenu predvoleného správania. Využitie atribútu „options“ pand nám umožnilo zmeniť toto správanie.
Pandy zobrazujú maximálny počet riadkov
Kedykoľvek sa pokúsite vytlačiť veľký dátový rámec, ktorý obsahuje viac riadkov a stĺpcov, ako je preddefinovaná prahová hodnota, výstup sa orezá. Ak chcete zobraziť všetky riadky v DataFrame, v tomto návode sa naučíte, ako upraviť možnosti zobrazenia Pandas. Pandy štandardne obmedzujú počet stĺpcov a riadkov, ktoré zobrazuje. Aj keď to môže byť užitočné pri čítaní obsahu, často to spôsobuje frustráciu, ak sa nezobrazujú informácie, ktoré potrebujete zobraziť. Tu použijeme metódy uvedené nižšie s ich syntaxou na zobrazenie všetkých stĺpcov dátového rámca.
natiahnuť()

set_option()

option_context()

Naučíme sa využitie všetkých týchto metód s praktickou implementáciou na zobrazenie maximálneho počtu riadkov v poskytnutom dátovom rámci.
Príklad č. 1: Použitie metódy Pandas to_string().
Táto ukážka nás naučí zobraziť maximálny počet riadkov v dátovom rámci na termináli pomocou metódy pandas „to_string()“.
Na kompiláciu a spustenie vzorových programov sme si vybrali nástroj „Spyder“. V tejto príručke použijeme tento nástroj na vykonanie všetkých našich príkladov. Spustili sme nástroj „Spyder“, aby sme mohli začať písať skript python. Počnúc kódom musíme najprv načítať potrebné knižnice do nášho python súboru, aby sme mohli používať jeho funkcie. Knižnica modulov, ktorú tu potrebujeme, sú „Pandy“. Takže sme ho importovali do nášho python súboru a priradili sme mu alias na „pd“.
Keďže hlavnou operáciou tohto článku je zobrazenie maximálneho počtu riadkov dátového rámca, najprv potrebujeme dátový rámec. Teraz je na vás, či uprednostníte vygenerovanie dátového rámca alebo import súboru CSV. Importovali sme vzorový súbor CSV. Na načítanie súboru CSV do programu python sme použili funkciu pandas „pd.read_csv()“. V zátvorkách tejto funkcie sme poskytli súbor CSV, ktorý chceme prečítať na displeji, čo je „industry.csv“. Vytvorili sme premennú „df“ na uloženie výstupu generovaného z čítania poskytnutého súboru CSV. Potom sme na zobrazenie dátového rámca zavolali metódu „print()“.
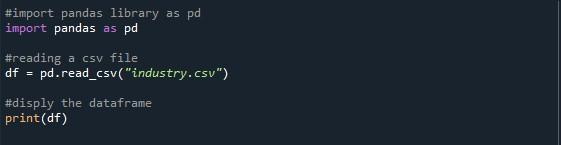
Keď spustíme tento program python stlačením možnosti „Spustiť súbor“, na konzole sa zobrazí dátový rámec. Môžete si všimnúť, že vo výsledku nižšie je 43 riadkov, ale zobrazených je len desať. Je to preto, že predvolená hodnota knižnice Pandas je iba 10 riadkov.
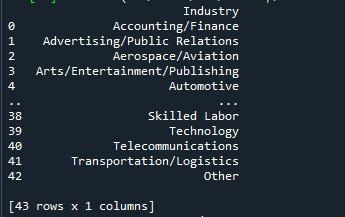
Na zobrazenie všetkých riadkov tu použijeme metódu pandas „to_string“. Najpriamejším spôsobom zobrazenia maximálneho počtu riadkov z dátového rámca je táto technika. Keďže však premení celý dátový rámec na jeden reťazec, neodporúča sa to pre veľmi veľké súbory údajov (v miliónoch). Napriek tomu to funguje efektívne pre množiny údajov, ktoré sú v dĺžke tisícov.
Pri funkcii „to_string()“ sme postupovali podľa vyššie uvedenej syntaxe. Jednoducho sme vyvolali metódu „to_string()“ s názvom nášho dátového rámca. Potom sme túto metódu umiestnili do funkcie „print()“, aby sme ju zobrazili pri volaní.

Výstupná snímka nám ukazuje dátový rámec so všetkými riadkami zobrazenými na termináli.
Príklad č. 2: Využitie metódy set_option Pandas
Druhou metódou, ktorú si v tejto príručke precvičíme, je panda „set_option()“ na zobrazenie maximálneho počtu riadkov poskytnutého dátového rámca.
V súbore python sme importovali knižnicu pandas, aby sme získali prístup k vyššie uvedenej funkcii. Na čítanie poskytnutého súboru CSV sme použili pandy „pd.read_csv()“. Vyvolali sme funkciu „pd.read_CSV()“ s názvom súboru CSV, ktorý chceme použiť, v zátvorkách, ktorým je „Sampledata.csv“. Pri importe súboru CSV majte na pamäti aktuálny pracovný adresár programu Python. Váš súbor CSV musí byť umiestnený v rovnakom adresári; v opačnom prípade sa zobrazí chybové hlásenie „súbor sa nenašiel“. Vytvorili sme premennú „sample“ na uloženie dátového rámca zo súboru CSV. Na zobrazenie tohto dátového rámca sme zavolali metódu „print()“.
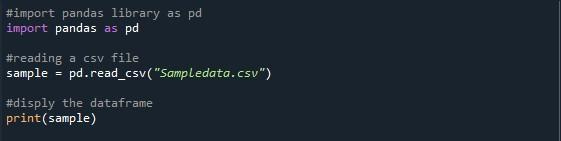
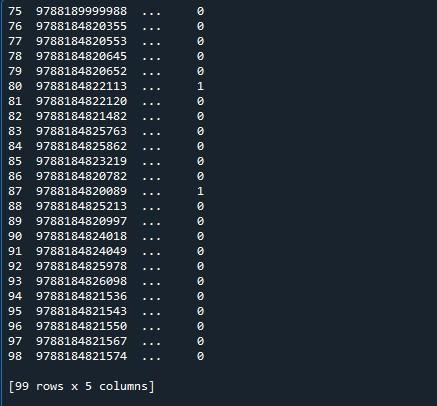
Tu máme náš výstup, kde sa zobrazuje iba desať riadkov. Maximálny uvedený počet riadkov je 99. Všetky ostatné riadky medzi prvými 5 a poslednými piatimi riadkami sú orezané.

Na zobrazenie maximálneho počtu riadkov, ktoré sú 99 pre tento dátový rámec, použijeme funkciu „set_option()“ modulu pandas. Pandy sa dodávajú s operačným systémom, ktorý vám umožňuje zmeniť správanie a zobrazenie. Táto metóda nám umožňuje nastaviť zobrazenie tak, aby zobrazovalo celý dátový rámec, a nie skrátený. Pandy poskytujú funkciu „set_ option()“ na zobrazenie všetkých riadkov dátového rámca.
Vyvolali sme „pd.set_option()“. Táto funkcia má parametre „display.max_rows“. „display.max_rows“ určuje maximálny počet riadkov, ktoré sa zobrazia pri zobrazení dátového rámca. Hodnota „max_rows“ je predvolene nastavená na 10. Ak je vybratá možnosť „None“, znamená to všetky riadky v dátovom rámci. Keďže chceme zobraziť všetky riadky, nastavíme ho na „Žiadne“. Nakoniec sme použili funkciu „print()“ na zobrazenie dátového rámca s maximálnym počtom riadkov.

Výsledkom je výsledok uvedený na snímke nižšie.
Príklad č. 3: Použitie metódy option_context() Pandas
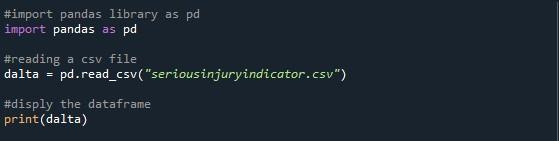
Posledná metóda, o ktorej tu diskutujeme, je „option_context()“ na zobrazenie všetkých riadkov dátového rámca. Na tento účel sme importovali balík pandas do súboru python a začali písať kód. Použili sme funkciu “pd.read_csv()” na prečítanie súboru CSV, ktorý sme zadali. Vytvorili sme premennú „dalta“ na uloženie dátového rámca zo zadaného súboru CSV. Potom sme jednoducho vytlačili dátový rámec pomocou metódy „print()“.
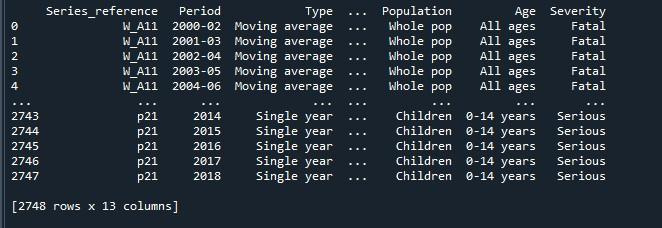
Výsledok, ktorý sme získali vykonaním vyššie uvedeného kódu, nám ukazuje dátový rámec so skrátenými riadkami.
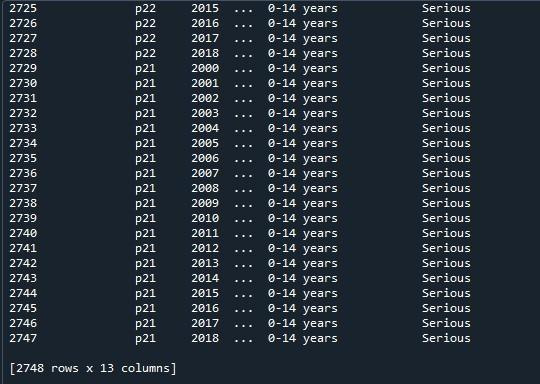
Teraz na tento dátový rámec použijeme pandy „pd.option_context()“. Táto funkcia je totožná s funkciou „set_option()“. Jediný rozdiel medzi týmito dvoma prístupmi je v tom, že „set_option()“ mení nastavenia natrvalo, zatiaľ čo „option _context()“ ich zmenil len vo svojom rozsahu. Táto metóda berie ako parameter aj riadky display.max, ktoré nastavíme na „None“, aby sa vykreslili všetky riadky dátového rámca. Po vyvolaní tejto funkcie sme ju len zobrazili pomocou metódy „print()“.

Tu si môžeme pozrieť kompletný dátový rámec s maximálnym počtom riadkov 2747.
Záver
Tento článok sa zameriava na možnosti zobrazenia pánd. Niekedy môžeme potrebovať zobraziť celý dátový rámec na termináli. Pandy nám na tento účel poskytujú rôzne možnosti. V tejto príručke sme použili tri z týchto stratégií. Prvý príklad bol založený na použití metódy „to_string()“. Naša druhá inštancia nás učí implementovať „set_option()“, zatiaľ čo posledná ilustrácia vykonáva metódu „option_context()“. Všetky tieto techniky sú demonštrované, aby sme vás oboznámili s alternatívnymi spôsobmi, ktoré nám pandy poskytujú na dosiahnutie požadovaného výsledku.