Syntax:
Existuje množstvo služieb, ktoré Hugging Face poskytuje, ale jednou z jeho široko používaných služieb je „API“. API umožňuje interakciu vopred vyškolenej AI a veľkých jazykových modelov s rôznymi aplikáciami. Hugging Face poskytuje rozhrania API pre rôzne modely, ako je uvedené nižšie:
- Modely generovania textu
- Prekladové modely
- Modely na analýzu sentimentov
- Modely pre vývoj virtuálnych agentov (inteligentných chatbotov)
- Klasifikácia a regresné modely
Poďme teraz objaviť spôsob, ako získať naše prispôsobené inferenčné API z Hugging Face. Aby sme to mohli urobiť, musíme sa najprv zaregistrovať na oficiálnej stránke Hugging Face. Pripojte sa k tejto komunite Hugging Face tým, že sa prihlásite na túto webovú stránku pomocou svojich poverení.
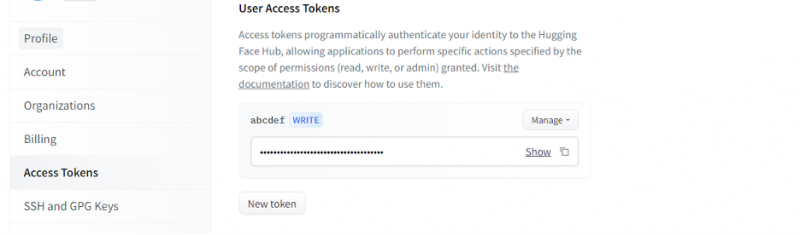
Keď získame účet na Hugging Face, teraz musíme požiadať o inferenčné API. Ak chcete požiadať o API, prejdite do nastavení účtu a vyberte „Prístupový token“. Otvorí sa nové okno. Vyberte možnosť „Nový token“ a potom vygenerujte token tak, že najprv zadáte názov tokenu a jeho rolu ako „ZAPÍSAŤ“. Vygeneruje sa nový token. Teraz musíme tento token uložiť. Až do tohto bodu máme náš žetón z Objímajúcej tváre. V ďalšom príklade uvidíme, ako môžeme použiť tento token na získanie inferenčného API.
Príklad 1: Ako vytvoriť prototyp s rozhraním Hugging Face Inference API
Doteraz sme diskutovali o spôsobe, ako začať s Hugging Face a inicializovali sme token z Hugging Face. Tento príklad ukazuje, ako môžeme použiť tento novo vygenerovaný token na získanie inferenčného API pre konkrétny model (strojové učenie) a pomocou neho robiť predpovede. Na domovskej stránke Hugging Face vyberte model, s ktorým chcete pracovať a ktorý je relevantný pre váš problém. Povedzme, že chceme pracovať s textovou klasifikáciou alebo modelom analýzy sentimentu, ako je uvedené v nasledujúcom úryvku zoznamu týchto modelov:
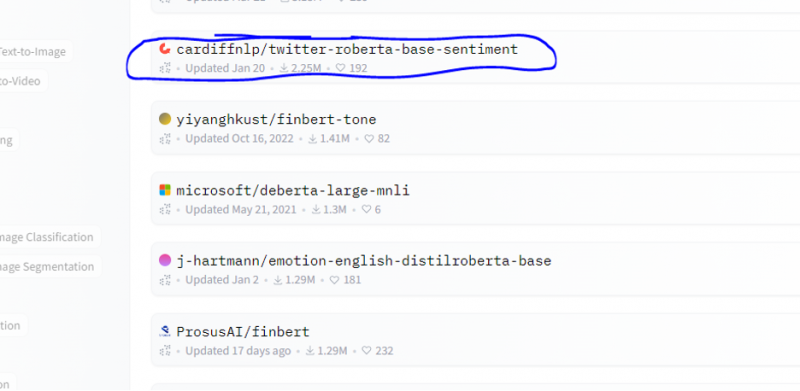
Z tohto modelu vyberáme model analýzy sentimentu.
Po výbere modelu sa zobrazí jeho karta modelu. Táto karta modelu obsahuje informácie o tréningových detailoch modelu a o tom, aké vlastnosti má model. Náš model je roBERTa-base, ktorý je natrénovaný na 58 miliónoch tweetov na analýzu sentimentu. Tento model má tri hlavné označenia triedy a kategorizuje každý vstup do príslušných označení triedy.
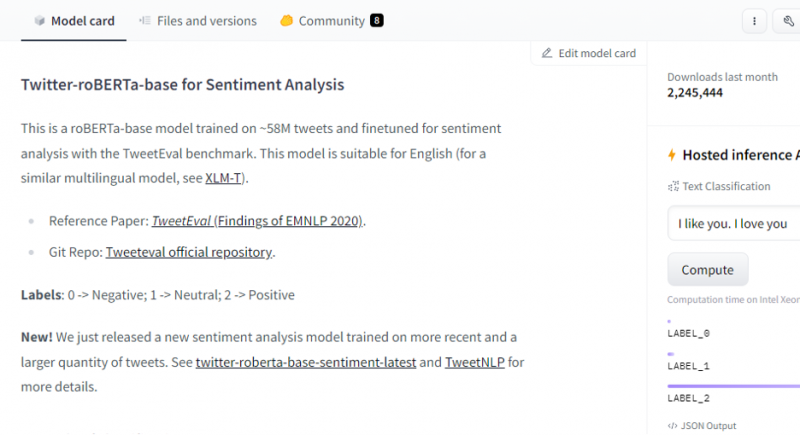
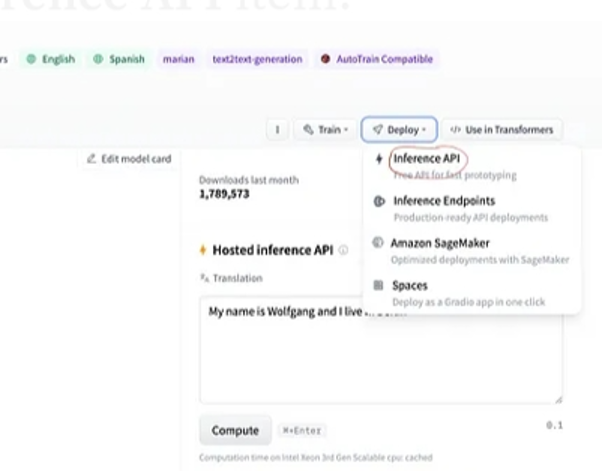
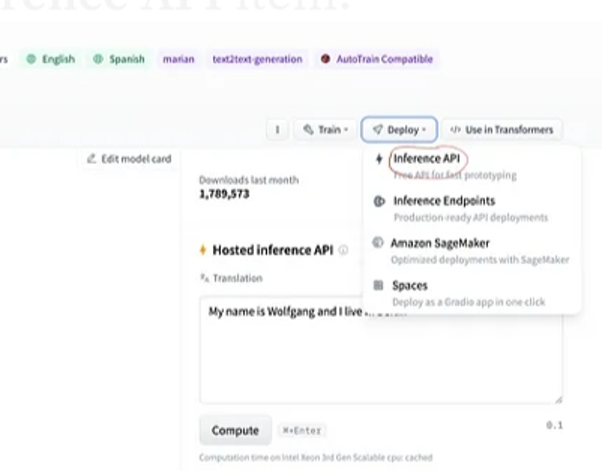
Ak po výbere modelu vyberieme tlačidlo nasadenia, ktoré sa nachádza v pravom hornom rohu okna, otvorí sa rozbaľovacia ponuka. Z tejto ponuky musíme vybrať možnosť „Inference API“.
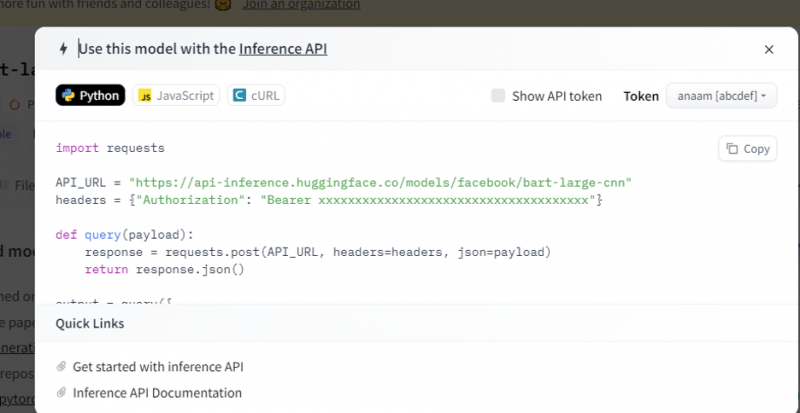
Rozhranie API na odvodenie potom poskytuje úplné vysvetlenie, ako používať tento konkrétny model s týmto odvodením, a umožňuje nám rýchlo vytvoriť prototyp pre model AI. Okno inferenčného API zobrazuje kód, ktorý je napísaný v skripte Pythonu.
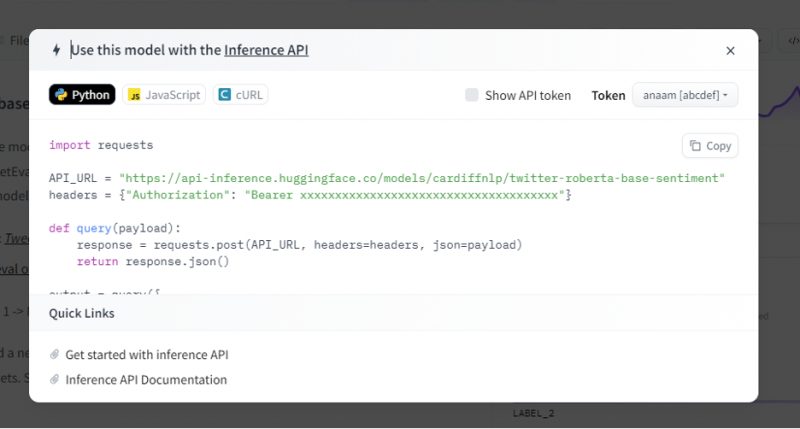
Skopírujeme tento kód a spustíme ho v ktoromkoľvek IDE Pythonu. Používame na to Google Colab. Po vykonaní tohto kódu v prostredí Python vráti výstup, ktorý prichádza so skóre a predpoveďou označenia. Toto označenie a skóre sú dané podľa nášho vstupu, pretože sme si vybrali model „analýzy sentimentu textu“. Potom je vstupom, ktorý dávame modelu, pozitívna veta a model bol vopred natrénovaný na tri triedy štítkov: štítok 0 znamená negatívne, štítok1 znamená neutrálny a štítok 2 je nastavený na pozitívny. Keďže naším vstupom je pozitívna veta, predikcia skóre z modelu je väčšia ako ostatné dve označenia, čo znamená, že model predpovedal vetu ako „pozitívnu“.
importovať žiadostiAPI_URL = 'https://api-inference.huggingface.co/models/cardiffnlp/twitter-roberta-base-sentiment'
hlavičky = { 'oprávnenie' : 'Nositeľ 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' }
def dopyt ( užitočné zaťaženie ) :
odpoveď = žiadosti. príspevok ( API_URL , hlavičky = hlavičky , json = užitočné zaťaženie )
vrátiť odpoveď. json ( )
výkon = dopyt ( {
'vstupy' : 'Cítim sa dobre, keď si so mnou' ,
} )
Výkon:

Príklad 2: Sumarizačný model prostredníctvom odvodenia
Postupujeme podľa rovnakých krokov, aké sú uvedené v predchádzajúcom príklade, a prototypujeme zbernicu súhrnného modelu pomocou jej inferenčného API z Hugging Face. Sumarizačný model je vopred natrénovaný model, ktorý sumarizuje celý text, ktorý mu dávame ako svoj vstup. Prejdite na účet Hugging Face, kliknite na model z horného panela s ponukami a potom vyberte model, ktorý je relevantný pre súhrn, vyberte ho a pozorne si prečítajte jeho kartu modelu.
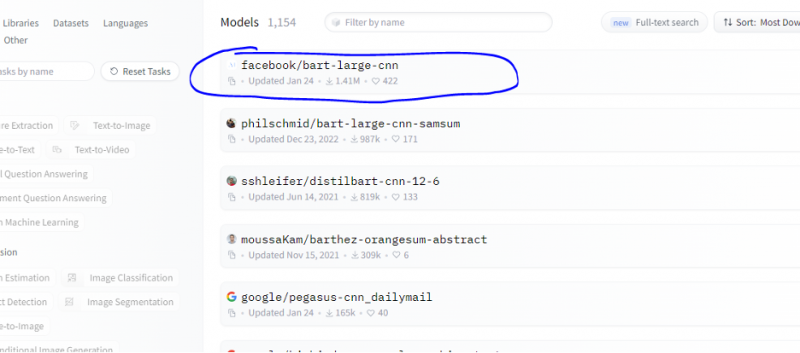
Model, ktorý sme si vybrali, je predtrénovaný model BART a je jemne prispôsobený súboru údajov CNN dennej pošty. BART je model, ktorý je najviac podobný modelu BERT, ktorý má kodér a dekodér. Tento model je účinný, keď je doladený na úlohy súvisiace s porozumením, sumarizáciou, prekladom a tvorbou textu.
Potom v pravom hornom rohu vyberte tlačidlo „nasadenie“ a z rozbaľovacej ponuky vyberte rozhranie API na odvodenie. Rozhranie API pre odvodenie otvorí ďalšie okno, ktoré obsahuje kód a pokyny na použitie tohto modelu s týmto odvodením.
Skopírujte tento kód a spustite ho v prostredí Python.
Model vracia výstup, ktorý je sumárom vstupu, ktorý sme do neho priviedli.

Záver
Pracovali sme na rozhraní API Hugging Face Inference a naučili sme sa, ako môžeme použiť programovateľné rozhranie tejto aplikácie na prácu s vopred pripravenými jazykovými modelmi. Dva príklady, ktoré sme urobili v článku, boli založené hlavne na modeloch NLP. Hugging Face API môže robiť zázraky, ak chceme vyvinúť rýchly prototyp poskytnutím rýchlej integrácie modelov AI do našich aplikácií. Stručne povedané, Hugging Face má riešenia na všetky vaše problémy od posilňovania až po počítačové videnie.