Táto príručka bude ilustrovať, ako používať VectorStoreRetrieverMemory pomocou rámca LangChain.
Ako používať VectorStoreRetrieverMemory v LangChain?
VectorStoreRetrieverMemory je knižnica LangChain, ktorú možno použiť na extrahovanie informácií/údajov z pamäte pomocou vektorových úložísk. Vektorové úložiská možno použiť na ukladanie a správu údajov na efektívne extrahovanie informácií podľa výzvy alebo dotazu.
Ak sa chcete naučiť proces používania VectorStoreRetrieverMemory v LangChain, jednoducho si prejdite nasledujúcu príručku:
Krok 1: Nainštalujte moduly
Spustite proces používania pamäťového retrievera inštaláciou LangChain pomocou príkazu pip:
pip install langchain
Nainštalujte moduly FAISS, aby ste získali údaje pomocou vyhľadávania sémantickej podobnosti:
pip install faiss-gpu 
Nainštalujte modul chromadb na používanie databázy Chroma. Funguje ako vektorový sklad na vytvorenie pamäte pre retrievera:
pip install chromadb 
Na inštaláciu je potrebný ďalší tiktoken modulu, ktorý možno použiť na vytvorenie tokenov konverziou údajov na menšie časti:
pip nainštalovať tiktoken 
Nainštalujte modul OpenAI, aby ste mohli používať jeho knižnice na vytváranie LLM alebo chatbotov pomocou jeho prostredia:
pip install openai 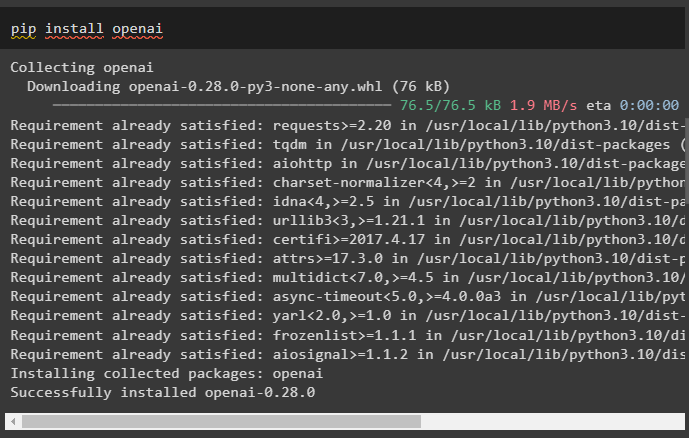
Nastavte prostredie na Python IDE alebo notebooku pomocou kľúča API z účtu OpenAI:
importovať vyimportovať getpass
vy . približne [ 'OPENAI_API_KEY' ] = getpass . getpass ( 'OpenAI API Key:' )
Krok 2: Importujte knižnice
Ďalším krokom je získanie knižníc z týchto modulov na používanie pamäťového retrievera v LangChain:
od langchain. výzvy importovať PromptTemplateod Dátum Čas importovať Dátum Čas
od langchain. llms importovať OpenAI
od langchain. vsadenia . openai importovať OpenAIEmbeddings
od langchain. reťaze importovať ConversationChain
od langchain. Pamäť importovať VectorStoreRetrieverMemory
Krok 3: Inicializácia Vector Store
Táto príručka používa databázu Chroma po importovaní knižnice FAISS na extrahovanie údajov pomocou príkazu input:
importovať faissod langchain. lekáreň importovať InMemoryDocstore
#importing knižnice na konfiguráciu databáz alebo vektorových úložísk
od langchain. vectorstores importovať FAISS
#create vloženia a texty na ich uloženie do vektorových obchodov
embedding_size = 1536
index = faiss. IndexFlatL2 ( embedding_size )
embedding_fn = OpenAIEmbeddings ( ) . embed_query
vectorstore = FAISS ( embedding_fn , index , InMemoryDocstore ( { } ) , { } )
Krok 4: Budovanie retrievera podporovaného vektorovým obchodom
Vytvorte si pamäť na ukladanie najnovších správ v konverzácii a získajte kontext rozhovoru:
retriever = vectorstore. ako_retriever ( search_kwargs = diktát ( k = 1 ) )Pamäť = VectorStoreRetrieverMemory ( retriever = retriever )
Pamäť. save_context ( { 'vstup' : 'Rád jem pizzu' } , { 'výkon' : 'fantastický' } )
Pamäť. save_context ( { 'vstup' : 'Som dobrý vo futbale' } , { 'výkon' : 'ok' } )
Pamäť. save_context ( { 'vstup' : 'Nemám rád politiku' } , { 'výkon' : 'samozrejme' } )
Otestujte pamäť modelu pomocou vstupu poskytnutého používateľom s jeho históriou:
vytlačiť ( Pamäť. load_memory_variables ( { 'výzva' : 'aký šport mám pozerať?' } ) [ 'história' ] ) 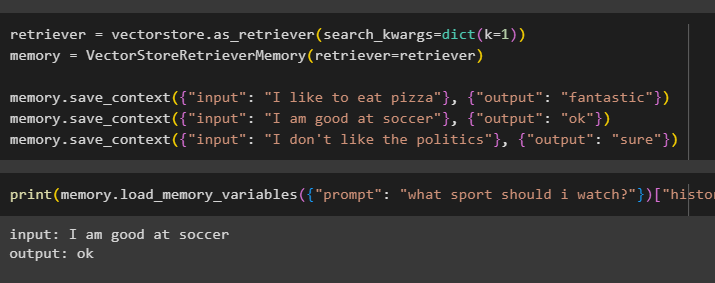
Krok 5: Použitie retrievera v reťazci
Ďalším krokom je použitie pamäťového retrievera s reťazcami vytvorením LLM pomocou metódy OpenAI() a konfiguráciou šablóny výzvy:
llm = OpenAI ( teplota = 0 )_DEFAULT_TEMPLATE = '''Je to interakcia medzi človekom a strojom
Systém vytvára užitočné informácie s podrobnosťami pomocou kontextu
Ak systém pre vás nemá odpoveď, jednoducho povie, že nemám odpoveď
Dôležité informácie z rozhovoru:
{história}
(ak text nie je relevantný, nepoužívajte ho)
Aktuálny chat:
Človek: {input}
AI:'''
PROMPT = PromptTemplate (
vstupné_premenné = [ 'história' , 'vstup' ] , šablóna = _DEFAULT_TEMPLATE
)
#nakonfigurujte ConversationChain() pomocou hodnôt pre jeho parametre
rozhovor_so_zhrnutím = ConversationChain (
llm = llm ,
výzva = PROMPT ,
Pamäť = Pamäť ,
podrobný = Pravda
)
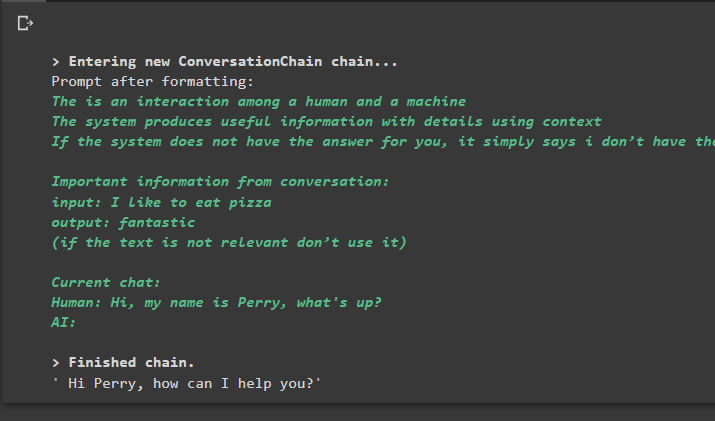
rozhovor_so_zhrnutím. predpovedať ( vstup = 'Ahoj, volám sa Perry, čo sa deje?' )
Výkon
Vykonaním príkazu sa spustí reťazec a zobrazí sa odpoveď poskytnutá modelom alebo LLM:
Pokračujte v konverzácii pomocou výzvy založenej na údajoch uložených vo vektorovom obchode:
rozhovor_so_zhrnutím. predpovedať ( vstup = 'aký je môj obľúbený šport?' ) 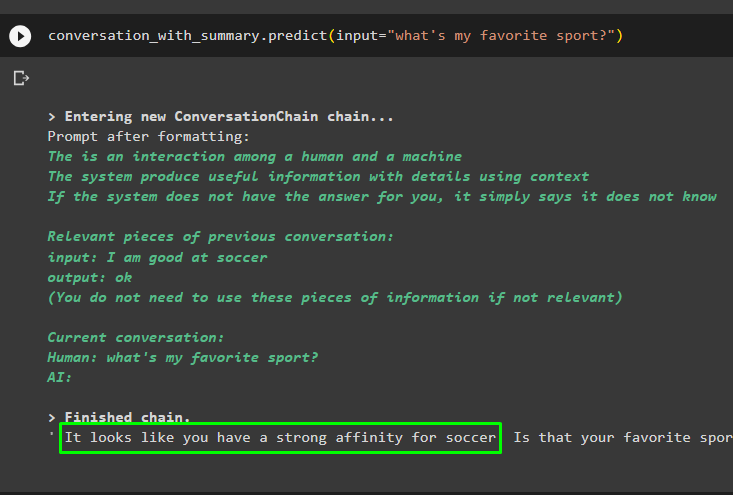
Predchádzajúce správy sú uložené v pamäti modelu, ktorú môže model použiť na pochopenie kontextu správy:
rozhovor_so_zhrnutím. predpovedať ( vstup = “Aké je moje obľúbené jedlo” ) 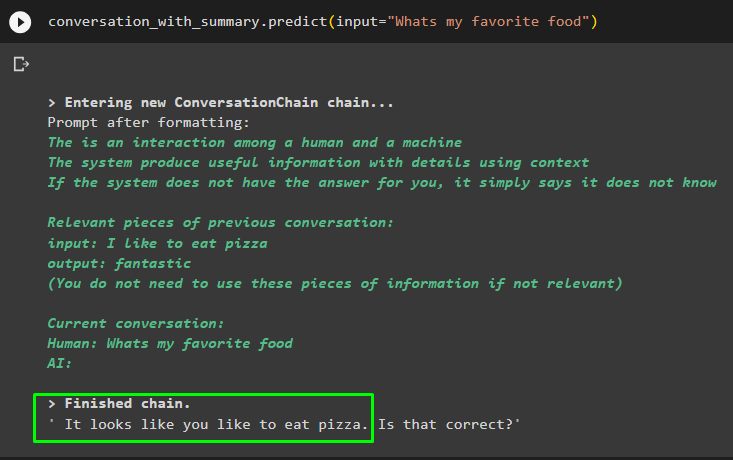
Získajte odpoveď poskytnutú modelu v jednej z predchádzajúcich správ a skontrolujte, ako pamäťový modul pracuje s modelom chatu:
rozhovor_so_zhrnutím. predpovedať ( vstup = 'Ako sa volám?' )Model správne zobrazil výstup pomocou vyhľadávania podobnosti z údajov uložených v pamäti:
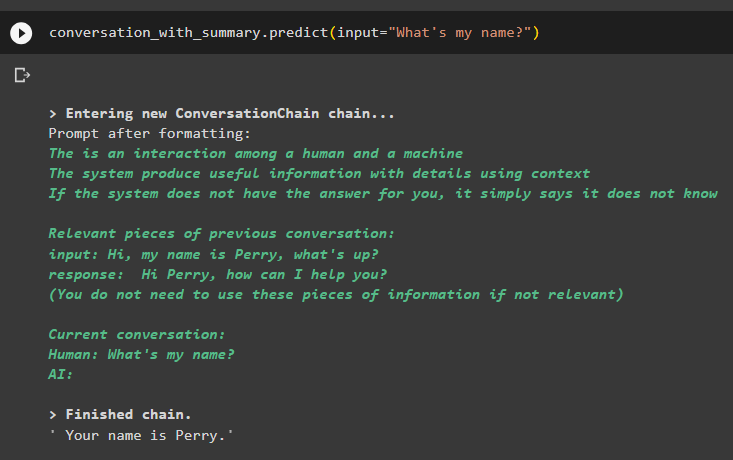
To je všetko o používaní vektorového retrievera v LangChain.
Záver
Ak chcete použiť pamäťový retriever založený na vektorovom úložisku v LangChain, jednoducho nainštalujte moduly a rámce a nastavte prostredie. Potom importujte knižnice z modulov na zostavenie databázy pomocou Chroma a potom nastavte šablónu výzvy. Po uložení údajov do pamäte otestujte retriever tak, že začnete konverzáciu a položíte otázky súvisiace s predchádzajúcimi správami. Táto príručka rozpracovala proces používania knižnice VectorStoreRetrieverMemory v LangChain.