C ++ je známy ako jeden z najrýchlejších programovacích jazykov s dobrým výkonom, vysokou presnosťou a primeraným systémom správy pamäte. Tento programovací jazyk tiež podporuje súbežné vykonávanie viacerých vlákien so zdieľaním viacerých zdrojov medzi nimi. Pri multithreadingu má vlákno vykonať iba operáciu čítania, ktorá nespôsobuje žiadne problémy, pretože vlákno nie je ovplyvnené tým, čo v tom čase robia ostatné vlákna. Ak však tieto vlákna museli medzi sebou zdieľať zdroje, jedno vlákno môže v tom čase upraviť údaje, čo spôsobuje problém. Na vyriešenie tohto problému máme C++ „Mutex“, ktorý zabraňuje prístupu viacerých zdrojov k nášmu kódu/objektu poskytnutím synchronizácie, ktorá uvádza, že prístup k objektu/kódu môže byť poskytnutý iba jednému vláknu naraz, takže viaceré vlákna by nemohli pristupovať k tomuto objektu súčasne.
Postup:
Dozvieme sa, ako môžeme zastaviť prístup viacerých vlákien k objektu naraz pomocou zámku mutex. Povieme si o syntaxi zámku mutex, o tom, čo je viacnásobné vlákno a ako môžeme riešiť problémy spôsobené viacerými vláknami pomocou zámku mutex. Potom si vezmeme príklad viacnásobného vlákna a implementujeme na ne zámok mutex.
Syntax:
Ak sa chceme dozvedieť, ako môžeme implementovať zámok mutex, aby sme mohli zabrániť prístupu viacerých vlákien súčasne k nášmu objektu alebo kódu, môžeme použiť nasledujúcu syntax:
$ std :: mutex mut_x
$mut_x. zámok ( ) ;
Void func_name ( ) {
$ // tu sa napíše kód, ktorý chceme skryť pred viacerými vláknami
$mut_x. odomkne ( ) ;
}
Teraz použijeme túto syntax na fiktívnom príklade a v pseudo kóde (ktorý nemôžeme spustiť tak, ako je v editore kódu), aby sme vám dali vedieť, ako môžeme presne použiť túto syntax, ako je uvedené nižšie:
$ std :: mutex mut_x
Prázdny blok ( ) {
$mut_x. zámok ( ) ;
$ std :: cout << 'Ahoj' ;
$mut_x. odomkne ( ) ;
}
Príklad:
V tomto príklade sa pokúsme najskôr vytvoriť operáciu s viacerými vláknami a potom túto operáciu obklopiť zámkom a odomknutím mutexu, aby sa zabezpečila synchronizácia operácie s vytvoreným kódom alebo objektom. Mutex sa zaoberá rasovými podmienkami, čo sú hodnoty, ktoré sú dosť nepredvídateľné a závisia od prepínania vlákien, ktoré sú časovo vedomé. Na implementáciu príkladu pre mutex musíme najprv importovať dôležité a požadované knižnice z repozitárov. Požadované knižnice sú:
$ # include
$ # include
$ # include
Knižnica „iostream“ nám poskytuje funkciu na zobrazenie údajov ako Cout, čítanie údajov ako Cin a ukončenie príkazu ako endl. Na využitie programov alebo funkcií z vlákien používame knižnicu „vlákno“. Knižnica „mutex“ nám umožňuje implementovať do kódu zámok aj odomknutie mutexu. Používame „# include“, pretože to umožňuje všetky programy súvisiace s knižnicou zahrnutou v kóde.
Teraz, po vykonaní predchádzajúceho kroku, definujeme triedu mutexu alebo globálnu premennú pre mutex pomocou std. Potom vytvoríme funkciu pre uzamknutie a odomknutie mutexu, ktorú by sme mohli neskôr zavolať v kóde. V tomto príklade túto funkciu pomenujeme ako blok. V tele funkcie bloku najskôr zavoláme „mutex.lock()“ a začneme písať logiku kódu.
Mutex.lock() zakazuje prístup ostatným vláknam, aby dosiahli náš vytvorený objekt alebo kód, takže iba jedno vlákno môže čítať náš objekt naraz. V logike spustíme cyklus for, ktorý beží na indexe od 0 do 9. Zobrazujeme hodnoty v slučke. Keď je táto logika vytvorená v zámku mutex po vykonaní jeho operácie alebo po ukončení logiky, zavoláme metódu „mutex.unlock()“. Toto volanie metódy nám umožňuje odomknúť vytvorený objekt zo zámku mutex, pretože prístup objektu k jednému vláknu bol poskytnutý skôr a keď operáciu na tomto objekte vykoná jedno vlákno naraz. Teraz chceme, aby k tomuto objektu alebo kódu mali prístup aj ostatné vlákna. V opačnom prípade sa náš kód pohybuje v situácii „zablokovania“, čo spôsobí, že vytvorený objekt s mutexom zostane navždy v uzamknutej situácii a žiadne iné vlákno by k tomuto objektu nemalo prístup. Preto sa stále vykonáva neúplná operácia. Potom opustíme funkciu bloku a presunieme sa do hlavnej.
V podstate jednoducho zobrazíme náš vytvorený mutex vytvorením troch vlákien pomocou „std :: vlákno názov_vlákna (volaním už vytvorenej blokovej funkcie, v ktorej sme vytvorili mutex)“ s názvami vlákno1, vlákno2 a vlákno3 atď. Týmto spôsobom sa vytvoria tri vlákna. Potom spojíme tieto tri vlákna, ktoré sa majú vykonať súčasne, volaním „názov_vlákna. pripojiť ()“. A potom vrátime hodnotu rovnú nule. Vyššie uvedené vysvetlenie príkladu je implementované vo forme kódu, ktorý je možné zobraziť na nasledujúcom obrázku:
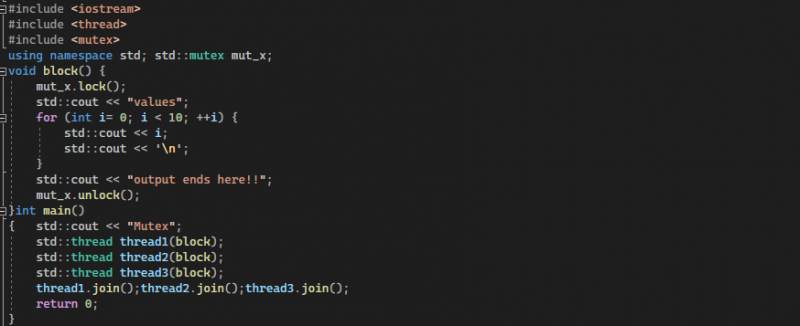
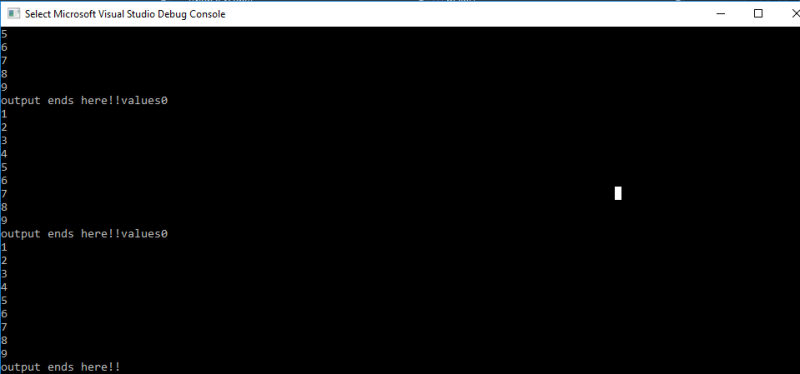
Vo výstupe kódu môžeme vidieť spustenie a zobrazenie všetkých troch vlákien po jednom. Vidíme aj to, či naša aplikácia patrí do kategórie multithreadingu. Napriek tomu žiadne z vlákien neprepísalo ani neupravilo údaje a nezdieľalo upravený zdroj z dôvodu implementácie mutexu „funkčného bloku“.
Záver
Táto príručka poskytuje podrobné vysvetlenie konceptu funkcie mutex používanej v C++. Diskutovali sme o tom, čo sú to multithreadingové aplikácie, s akými problémami sa stretávame v multithreadingových aplikáciách a prečo potrebujeme implementovať mutex pre multithreadingové aplikácie. Potom sme diskutovali o syntaxi pre mutex s fiktívnym príkladom pomocou pseudokódu. Potom sme implementovali kompletný príklad na multithreadingových aplikáciách s mutexom vo vizuálnom štúdiu C++.