Ako správcovia databáz musíme byť posadnutí nástrojmi a metódami na zvýšenie výkonu databázy.
V PostgreSQL máme prístup k príkazu EXPLAIN ANALYZE, ktorý nám umožňuje analyzovať plán vykonávania a výkon daného databázového dotazu. Príkaz vráti podrobné informácie o tom, ako databázový stroj spracováva dotaz. To zahŕňa postupnosť vykonaných operácií, odhadované náklady na dotaz, načasovanie vykonávania a ďalšie.
Tieto informácie potom môžeme použiť na identifikáciu databázových dotazov, ako aj na identifikáciu a opravu potenciálnych prekážok výkonu.
Tento tutoriál popisuje, ako použiť príkaz EXPLAIN ANALYZE v PostgreSQL na zobrazenie a optimalizáciu výkonu dotazu.
PostgreSQL EXPLAIN ANALYZE
Príkaz je celkom jednoduchý. Najprv musíme na začiatok dotazu, ktorý chceme analyzovať, pridať príkaz EXPLAIN ANALYZE.
Syntax príkazu je nasledovná:
EXPLAIN ANALYZEPo vykonaní príkazu PostgreSQL vráti podrobný výstup o poskytnutom dotaze.
Pochopenie výstupu dotazu EXPLAIN ANALYZE
Ako už bolo spomenuté, akonáhle spustíme príkaz EXPLAIN ANALYZE, PostgreSQL vygeneruje podrobnú správu o pláne dotazov a štatistike vykonávania.
Výstup sa skladá zo sady stĺpcov, ktoré obsahujú užitočné informácie. Výsledné stĺpce sú zobrazené s príslušným významom:
PLÁN QUERY – Tento stĺpec zobrazuje plán vykonávania zadaného dotazu. Plán vykonávania sa vzťahuje na postupnosť operácií, ktoré databázový mechanizmus vykoná na úspešné dokončenie dotazu.
PLÁNOVAŤ – Druhý stĺpec je stĺpec PLÁN. Obsahuje textovú reprezentáciu každej operácie alebo kroku v pláne vykonávania. Opäť platí, že každá operácia je odsadená, aby naznačila hierarchiu operácií.
CELKOVÉ NÁKLADY – Stĺpec celkových nákladov predstavuje odhadované celkové náklady na dotaz. Cena sa vzťahuje na relatívnu mieru, ktorú plánovač databázových dotazov používa na určenie optimálneho plánu vykonávania.
SKUTOČNÉ RIADKY – Tento stĺpec zobrazuje presný počet riadkov, ktoré sú spracované v každom kroku vykonávania dotazu.
SKUTOČNÝ ČAS – Tento stĺpec zobrazuje skutočný čas každej operácie, ktorý zahŕňa čas vykonania operácie aj čas strávený na zdrojoch.
ČAS PLÁNOVANIA – Tento stĺpec zobrazuje čas, ktorý potrebuje plánovač dotazov na vygenerovanie plánu vykonávania. To zahŕňa celkový čas optimalizácie dotazu a generovania plánu.
ČAS VYKONANIA – Tento stĺpec zobrazuje celkový čas vykonania dotazu. To zahŕňa aj čas strávený plánovaním a časom vykonania dotazu.
PostgreSQL EXPLAIN ANALYZE Príklad
Pozrime sa na niekoľko základných príkladov použitia príkazu EXPLAIN ANALYZE.
Príklad 1: Vyberte príkaz
Použime príkaz EXPLAIN ANALYZE na zobrazenie vykonania jednoduchého príkazu select v PostgreSQL.
Po spustení predchádzajúceho príkazu by sme mali dostať nasledujúci výstup:
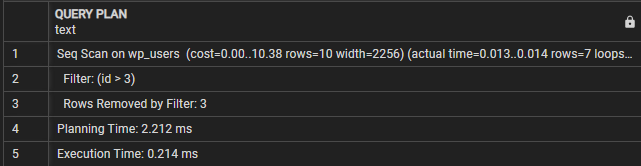
PLÁN QUERY-------------------------------------------------- -----------------
Seq Scan on wp_users (cena=0,00..10,38 riadkov=10 šírka=2256) (skutočný čas=0,009..0,010 riadkov=7 slučiek=1)
Filter: (id > 3)
Riadky odstránené filtrom: 3
Čas plánovania: 0,995 ms
Čas vykonania: 0,021 ms
(5 riadkov)
V tomto prípade môžeme vidieť, že časť Plán dotazov označuje, že dotaz vykonáva sekvenčné skenovanie tabuľky wp_users. Čiara filtra označuje podmienku, ktorá sa používa na filtrovanie výsledných riadkov.
Potom uvidíme „Riadky odstránené filtrom“, ktorá zobrazuje počet riadkov, ktoré boli odstránené podmienkou filtra.
Nakoniec čas vykonania zobrazuje celkový čas vykonania dotazu. V tomto prípade dopyt trvá 0,021 ms.
Príklad 2: Analýza spojenia
Zoberme si zložitejší dotaz, ktorý zahŕňa spojenie SQL. Na tento účel používame vzorovú databázu Pagila. Vzorovú databázu si môžete stiahnuť a nainštalovať do svojho počítača na účely demonštrácie.
Môžeme spustiť jednoduché spojenie, ako je znázornené na nasledujúcom obrázku:
vysvetliť analyzovať SELECT titulok, menoZ filmu f
PRIPOJTE SA k filmovej_kategórii fc ON f.film_id = fc.film_id
JOIN category c ON fc.category_id = c.category_id;
Po spustení daného dotazu by sme mali vidieť výstup takto:
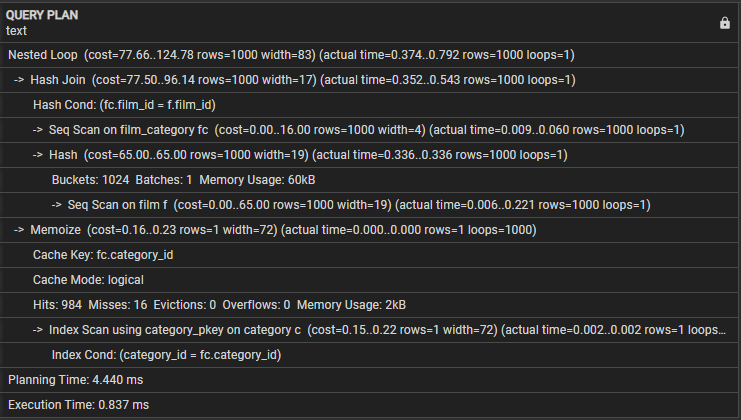
Poďme preskúmať nasledujúci plán dopytov:
- Vnorená slučka – označuje, že spojenie používa stratégiu spojenia vnorenej slučky.
- Hash Join – Táto operácia spája film_category a filmové tabuľky pomocou algoritmu Hash join. Táto operácia má náklady 77,50 a odhaduje sa na 1000 riadkov. Skutočný čas potrebný na túto operáciu je však 0,254 až 0,439 milisekúnd a získa 1 000 riadkov.
- Hash Cond – Označuje, že podmienka spojenia používa spojenie Hash na zhodu so stĺpcami film_id a film_category v tabuľkách filmov.
- Seq Scan on film_category – Táto operácia vykoná sekvenčné skenovanie v tabuľke film_category s cenou 16,00 a odhadovaným počtom 1000 riadkov. Skutočný čas potrebný na túto operáciu je 0,008 až 0,056 milisekúnd a získa 1 000 riadkov.
- Seq Scan on film – Dotaz vykoná sekvenčné skenovanie na filmovej tabuľke s výslednými odhadovanými a skutočnými nákladmi a riadkami v tejto operácii.
- Memoize – Táto operácia ukladá do vyrovnávacej pamäte výsledky spojenia medzi film_category a filmovými tabuľkami na následné použitie.
- Kľúč vyrovnávacej pamäte – označuje, že kľúč vyrovnávacej pamäte, ktorý sa používa na zapamätanie, je založený na stĺpci category_id z film_category.
- Režim vyrovnávacej pamäte – označuje, že dotaz používa režim logickej vyrovnávacej pamäte.
- Hity, Misses, Evictions, Overflows – Tri riadky poskytujú štatistiky o vyrovnávacej pamäti, počte zásahov, zmeškaných, vysťahovaniach a pretečeniach počas vykonávania. Tento blok zahŕňa aj využitie pamäte počas vykonávania dotazu.
- Prehľadávanie indexu pomocou category_pkey – Zobrazuje operáciu, ktorá vykonáva prehľadávanie indexu v tabuľke kategórií pomocou indexu primárneho kľúča.
- Index Cond – Ukazuje, že skenovanie indexu je založené na podmienke, ktorá sa zhoduje so stĺpcom category_id v tabuľke kategórií.
- Čas plánovania – Tento riadok zobrazuje čas potrebný na plánovanie dotazu, ktorý je 3,005 milisekúnd.
- Čas vykonania – Nakoniec tento riadok zobrazuje celkový čas vykonania dotazu, ktorý je 0,745 milisekúnd.
Tu to máte! Podrobné informácie o vykonaní jednoduchého spojenia v PostgreSQL.
Záver
Objavili ste silu a využitie príkazu EXPLAIN ANALYZE v PostgreSQL. Príkaz EXPLAIN ANALYZE je výkonný nástroj na analýzu a optimalizáciu dotazov. Použite tento nástroj na vytváranie efektívnych a menej zdrojovo náročných dotazov.