„Pandy“ sú skvelým jazykom na vykonávanie analýzy údajov vďaka svojmu skvelému ekosystému balíkov python zameraných na údaje. To uľahčuje analýzu a import oboch faktorov. Smerodajná odchýlka je „typická“ odchýlka odvodená od priemeru. Používa sa veľa, keďže vracia pôvodné merné jednotky dátového rámca. Pandy použili std() na výpočet štandardnej odchýlky. Smerodajnú odchýlku je možné vypočítať z daných hodnôt, ktoré môžu byť v dátovom rámci vo forme riadku alebo stĺpca. Budeme implementovať všetky možné spôsoby použitia štandardnej odchýlky pandy. Na implementáciu kódu použijeme nástroj „spyder“, keďže je napísaný v prostredí prijateľnom pre python.“
Syntax
'df.std ( ) “
Nasledujúca syntax sa používa na výpočet štandardnej odchýlky v dátovom rámci. „df“ v dátovom rámci je skratka pre dátový rámec. Čo robí štandardná odchýlka? Meria rozsah požadovaných údajov. Čím viac rozšírených vysokých hodnôt, tým vyššia by mala byť štandardná odchýlka.
Návrat
Štandardná odchýlka pandy vráti dátový rámec, ak je úroveň špecifikovaná na základe požiadavky.
Všimnite si, že funkcia „std()“ bude pri výpočte štandardnej odchýlky pandy automaticky ignorovať hodnoty „NaN“ v „df“. „NaN“ možno vysvetliť ako „nie je číslo“, čo znamená, že konkrétnemu subjektu nie je priradená žiadna hodnota.
Nasledujú metódy, ktoré sa vykonajú s príkladmi štandardnej odchýlky pandy:
-
- Výpočet štandardnej odchýlky Pandy v jednom stĺpci.
- Výpočet štandardnej odchýlky Pandy vo viacerých stĺpcoch.
- Výpočet štandardnej odchýlky Pandy pre všetky číselné stĺpce.
- štandardná odchýlka pandy pomocou osi = 1.
- štandardná odchýlka pandy s použitím osi = 0.
Vytvorenie dátového rámca pre výpočet štandardnej odchýlky v Pandách
Najprv otvorte softvér „spyder“. Teraz importujte knižnicu pandy ako pd. Vytvoríme dátový rámec, ktorý pozostáva z hodnotiacej tabuľky s výrazmi „x“, „y“ a „z“ s ich bodmi ako „22“, „10“, „11“, „16“, „12“, „45“. “, „36“ a „40“. Ich hodnoty asistencií máme ako „8“, „9“, „13“, „7“, „22“, „24“, „4“ a „6“, pričom hodnoty doskokov majú aj hodnotu „17“, „ 14“, „3“, 5, „9“, „8“, „7“ a „4“.
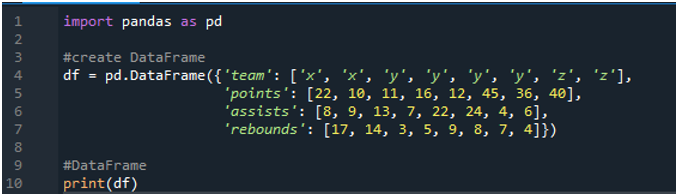
Displej zobrazuje vytvorený dátový rámec podľa hodnôt priradených v kóde:

Príklad č. 01: Výpočet štandardnej odchýlky Pandas v jednom stĺpci
V tomto príklade vypočítame smerodajnú odchýlku jedného stĺpca v dátovom rámci pandy. Dátový rámec má hodnoty tímu ako „u“, „v“ a „b“ s ich bodmi ako „44“, „33“, „22“, „44“, „45“, „88“, „96“. “ a „78“. Hodnoty asistencií sú „7“, 8, „9“, „10“, „11“, „14“, „18“ a „17“, pričom hodnoty doskokov majú aj hodnoty „11“, „ 9“, „8“, „7“, „6“, „5“, „4“ a „3“. Stĺpec „body“ sa vyberie z dátového rámca na výpočet štandardnej odchýlky jedného stĺpca.
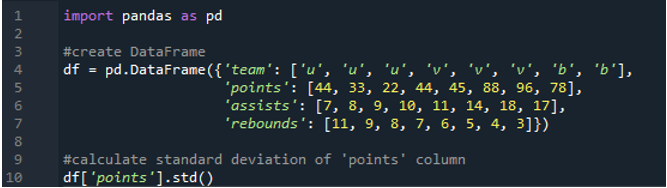
Výstup zobrazuje štandardnú odchýlku vypočítanú zo stĺpca „body“:

Príklad č. 02: Výpočet štandardnej odchýlky Pandas vo viacerých stĺpcoch
V tomto príklade vykonáme výpočty štandardnej odchýlky pre pandy vo viacerých stĺpcoch. V tomto dátovom rámci sú dáta opäť zo športovej tabuľky s hodnotami tímu ako „n“, „w“ a „t“ so skóre ako „33“, „22“, „66“, „55“, „44“, „88“, „99“ a „77“. Asistencie ako „9“, „7“, „8“, „11“, „16“, „14“, „12“ a „13“ a doskoky ako „5“, „8“, „1“, „ 2“, „3“, „4“, „6“ a „7“. Tu vypočítame štandardnú odchýlku dvoch stĺpcov „body“ a „odskoky“ pomocou funkcie std() aplikovanej na dátový rámec.
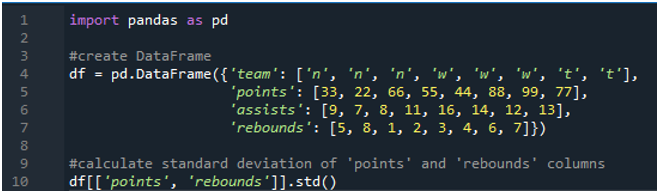
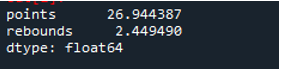
Ako vidíme, výstup ukazuje, že štandardná odchýlka bola 26,944387 v stĺpci bodov a 2,449490 v stĺpci odrazu.
Príklad č. 03: Výpočet štandardnej odchýlky Pandas všetkých číselných stĺpcov
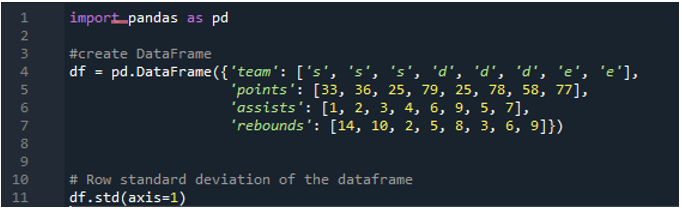
Teraz sme sa naučili, ako vypočítať smerodajnú odchýlku jedného a viacerých riadkov. Čo ak nechceme špecifikovať všetky názvy stĺpcov v dataframe a vypočítať celý dataframe? To je možné len pomocou jednoduchej funkcie implementácie štandardnej odchýlky pandy pre výpočet celého dátového rámca vo výsledkoch. Dátový rámec sa skladá z „l“, „m“ a „o“ s bodovými hodnotami „33“, „36“, „79“, „78“, „58“, „55“ a dva tímy dosahujú rovnaké skóre. to je '25'. Asistencie sú „1“, „2“, „3“, „4“, „6“, „9“, „5“ a „7“ a ich doskoky ako „14“, „10“, „2“ , „5“, „8“, „3“, „6“ a „9“. Všetky štandardné odchýlky stĺpcov môžeme vypočítať podľa pandy v dátovom rámci pomocou funkcie pandas „std()“.
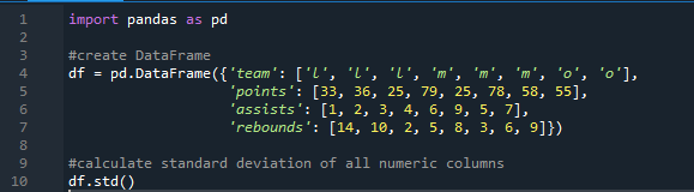
Displej má vypočítanú štandardnú odchýlku celého „df“ znázorneného nižšie; môžeme si tiež všimnúť, že pandy nevypočítali smerodajnú odchýlku prvého stĺpca, ktorý je „tím“, pretože to nie je číselný stĺpec.
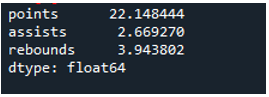
Príklad č. 04: Štandardná odchýlka Pandy s použitím osi = 0
V tomto príklade majú dátové rámce tímy športov ako „g“, „h“ a „k“ s ďalšími údajmi. Tu vypočítame štandardnú odchýlku pomocou osi ako „0“, parametra používaného v štandardnej odchýlke pandy. Tento argument vypočíta štandardnú odchýlku po stĺpcoch dátového rámca.
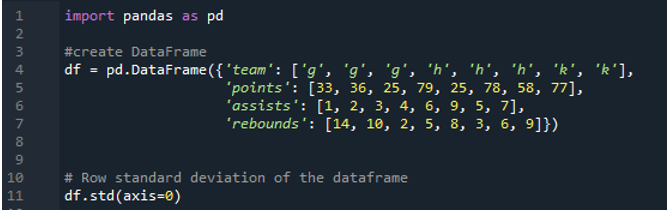
Nasledujúci výstup zobrazuje výsledky v stĺpcoch vypočítanej smerodajnej odchýlky. Stĺpec bodov má vypočítanú štandardnú odchýlku ako „24,0313062“, stĺpec asistencií má vypočítanú štandardnú odchýlku ako „2,669270“ a vypočítaná štandardná odchýlka v stĺpci odrazu je zobrazená ako „3,943802“.
Príklad č. 05: Štandardná odchýlka Pandy s použitím osi = 1
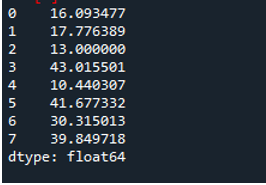
Tu použijeme parameter osi priradený ako „1“ na výpočet štandardnej odchýlky v pandách. Aký rozdiel môže spôsobiť os „1“? Argument osi „1“ vypočíta štandardnú odchýlku po riadkoch číselných hodnôt v dátovom rámci. Dátový rámec má tri tímy ako „s“, „d“ a „e“, s pridaním údajových stĺpcov vytvorených ako body tímu, asistencie tímu a doskoky tímu. Všetky smery majú v dátovom rámci priradené rôzne hodnoty. Tento parameter osi je taká zmena hry, pretože časom musíme pracovať s údajmi tam, kde ich chceme mať, v stĺpci plus bod vypočítaný z vykonanej štandardnej odchýlky.
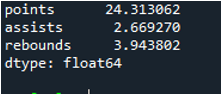
Nasledujúci výstup zobrazuje štandardnú odchýlku vypočítanú v riadku dátového rámca:
Záver
Štandardná odchýlka Pandy je veľmi technická funkcia, ktorá je veľmi prospešnou funkciou, pretože zisťuje štandardnú odchýlku paktu nadšenia dátových rámcov pandy. V tomto úvodníku sme študovali metódy výpočtu štandardnej odchýlky u pand. Urobili sme jednostĺpcové výpočty smerodajnej odchýlky a viacerých stĺpcov a spoločne sme vypočítali aj smerodajnú odchýlku celého dátového rámca. Všetky stratégie fungujú dobre, pokiaľ sa používajú dôsledne a s požadovanými výsledkami.