Pozrime sa teraz na nástroj iconv Linuxu v jeho terminálovej konzole. Takže sme vykonávali inštrukciu „iconv“ s príznakom „-l“, aby sme zobrazili všetky známe a najpoužívanejšie kódované znakové sady na obrazovke nášho terminálu. Zobrazí kódované znakové sady spolu s ich aliasmi. Po miernom rolovaní nadol môžete vidieť dlhý zoznam kódovaných znakových sád.
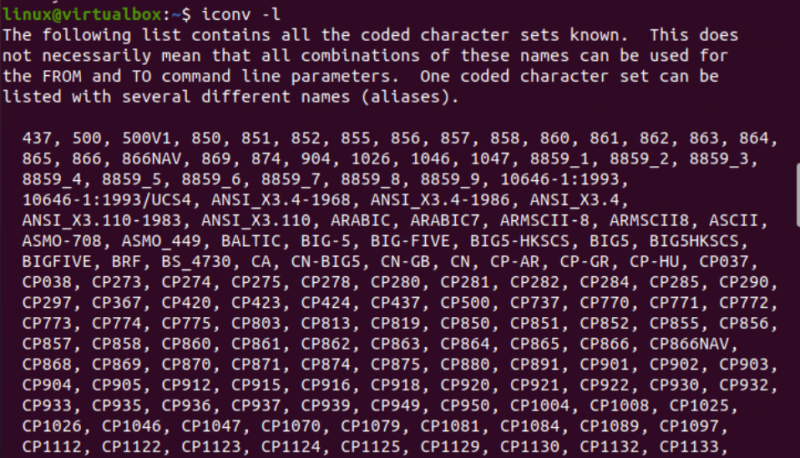
Teraz je čas začať s implementáciou príkazu iconv v systéme Linux. Po prvé, v našom systéme potrebujeme rôzne typy súborov na konverziu jedného typu súboru na iný typ. Preto využívame „dotykový“ dotaz na konzolovom termináli na vytvorenie troch rôznych súborov, t. j. typu Java, typu C a typu textu. Vypísaním aktuálneho obsahu adresára v ňom nájdete novovygenerované súbory.
Potom sa pozrieme na typ každého súboru samostatne pomocou dotazu „súbor“ spolu s názvom každého súboru. Tento dotaz vyžaduje voľbu „-I“, aby sa zobrazil typ kódovacej znakovej sady pre každý súbor samostatne. Ak ste zabudli použiť možnosť „-I“, použite namiesto toho príznak „—mime“. Príznaky „-I“ aj „—mime“ fungujú rovnako.
Teraz, po vykonaní inštrukcie „súbor“ pre súbor typu „txt“, sme dostali kódovanie typu znakov „US-ASCII“. Pri použití rovnakej inštrukcie pre súbory Java a C sa ukazuje, že oba súbory obsahujú kódovanie typu znakov „BINARY“. Spolu s tým táto inštrukcia ukazuje, že všetky tieto tri súbory sú prázdne.
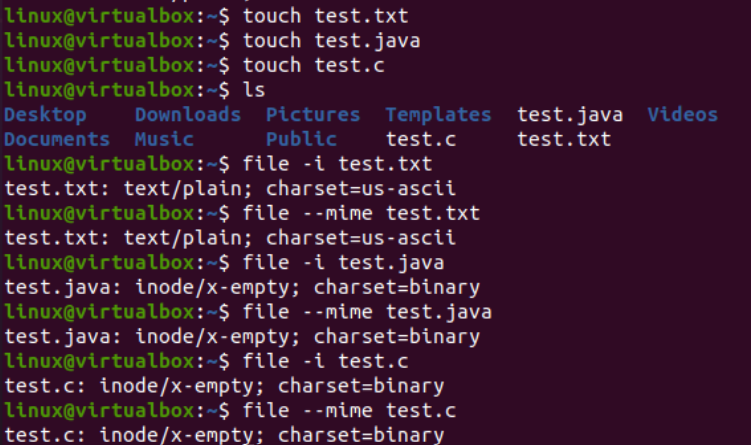
Teraz si ukážeme použitie inštrukcie iconv na konzole na prevod konkrétneho súboru kódovania znakovej sady na iné kódovanie znakovej sady. Predtým musíme do našich súborov pridať nejaký kód alebo údaje. Preto sme pridali kód Java do súboru „text.java“, kód C do súboru „text.c“ a pridali textové údaje do súboru „test.txt“. Dotaz mačka sa tu použil na zobrazenie obsahu všetkých troch súborov, ako je uvedené nižšie:
Teraz, keď sme úspešne pridali údaje, znova uvidíme kódovanie znakovej sady týchto súborov. Vyskúšali sme teda rovnakú inštrukciu súboru v rámci shellu s príznakom „-I“ a názvami súborov, t. j. test.txt, test.java a test.c. Spustenie týchto troch pokynov oddelene pre všetky tri súbory ukazuje, že kódovanie znakovej sady bolo aktualizované pre súbory Java a C, pričom pre textový súbor zostalo rovnaké, t. j. US-ASCII. Kódovanie súborov Java a C bolo predtým „binárne“; teraz je to „US-ASCII“. Tiež to ukazuje, že textový súbor obsahuje údaje vo formáte obyčajného textu, zatiaľ čo ďalšie dva súbory kódu obsahujú skripty ako obsah.

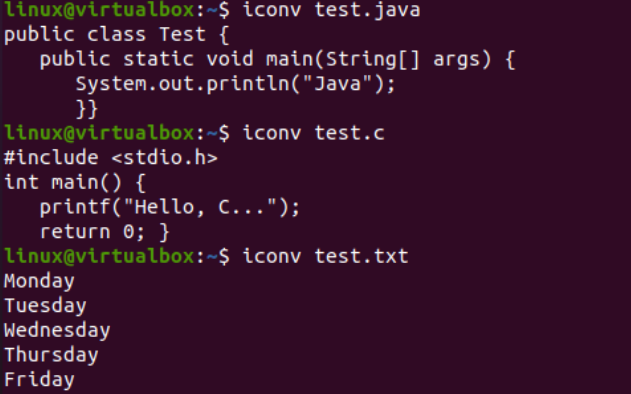
Je čas vykonať skutočnú úlohu potrebnú pre tento článok, t. j. previesť jedno kódovanie na iné pomocou príkazu iconv v shelli. Používali sme teda inštrukciu „iconv“ v rámci shellového terminálu s oprávneniami „sudo“. Tento príkaz preberá možnosť „-f“ znamená „od“ a možnosť „-t“ znamená „do“, t. j. z jedného kódovania do druhého.
Po voľbe „-f“ musíte zadať kódovanie, ktoré už váš súbor má, t. j. US-ASCII. Zatiaľ čo za voľbou „-t“ musíte zadať kódovanie, ktoré chcete nahradiť starým kódovaním, t. j. UNICODE. Ak chcete vytvoriť obraz objektu, musíte zadať názov súboru použitého ako zdroj pomocou voľby –o. Obrázok objektu by bol iný súbor, t. j. „new.c“, rovnakého typu, ale s novým kódovaním a rovnakými údajmi.
Po vykonaní nasledujúceho pokynu získate nový súbor v rovnakom adresári, t. j. podľa dotazu „ls“. Teraz skontrolujeme kódovanie znakovej sady nového súboru vygenerovaného pomocou inštrukcie iconv. Opäť použijeme inštrukciu „súbor“ s voľbou „-I“ a novým názvom súboru, t.j. new.c.
Uvidíte, že znaková sada pre tento nový súbor sa líši od znakovej sady starého súboru, t. j. znakovej sady UTF-16LE. Je to preto, že sme preložili kódovanie US-ASCII do kódovania UNICODE pomocou inštrukcie iconv pre náš súbor new.c. Dotaz „cat“ zobrazil v súbore rovnaký kód C, ale začal s niektorými znakmi Unicode, ako už bolo uvedené.
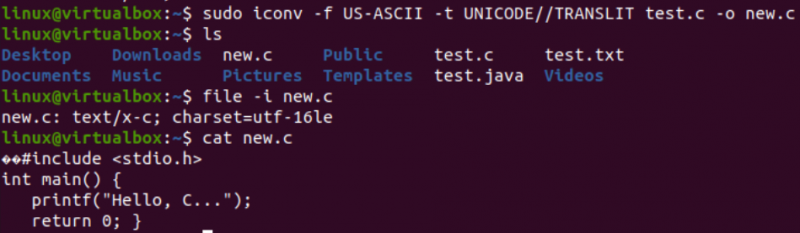
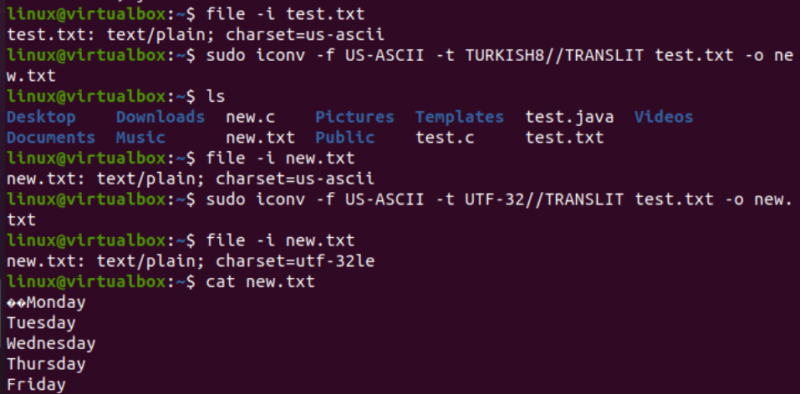
Veľmi podobným spôsobom zmeníme kódovanie textového súboru test.txt. Inštrukcia súboru ukazuje, že má kódovanie znakovej sady US-ASCII. Príkaz iconv bol použitý v rovnakom formáte na konverziu kódovania súboru test.txt z US-ASCII na TURECKO8. Uvidíte, že nezmení US-ASCII na turečtinu.
Potom sme použili rovnaký príkaz na pokrytie kódovania znakovej sady US-ASCII až UTF-32 pre rovnaký súbor. Tentoraz to funguje. Je to preto, že niekedy môže nastať problém s prevodom jednej sady kódovania na inú, alebo to druhé kódovanie nemusí podporovať.
Záver
Tento článok popisuje, ako používať pokyny iconv Linux na konverziu jednej kódovacej znakovej sady na inú pomocou ich aliasov. Týmto spôsobom sme museli vytvoriť niekoľko súborov rôznych typov.