Tento článok bude diskutovať o tom, ako používať rozhranie Elasticsearch multi-get API na načítanie viacerých dokumentov JSON na základe ich ID. Okrem toho vám Elasticsearch umožňuje použiť jeden dotaz na získanie dokumentov na získanie dokumentov z indexov iba pomocou ID dokumentov.
Poďme preskúmať.
Požiadať o syntax
Nasleduje syntax pre rozhranie Elasticsearch multi-get API:
GET /_mget
GET /
Multi-get API podporuje viacero indexov, čo vám umožňuje načítať dokumenty, aj keď nie sú v rovnakom indexe.
Požiadavka podporuje nasledujúce parametre cesty:
-
– Názov indexu, z ktorého sa majú načítať dokumenty podľa ich ID.
Môžete tiež zadať ďalšie parametre dopytu, ako je znázornené:
- Prednosť – Definuje preferovaný uzol alebo zlomok.
- Reálny čas – Ak je nastavené na hodnotu true, operácia sa vykoná v reálnom čase.
- Obnoviť – Vynúti operáciu obnoviť cieľové zlomky pred načítaním špecifikovaných dokumentov.
- Smerovanie – Hodnota, ktorá sa používa na smerovanie operácií do konkrétneho zlomku.
- Store_fields – Obnoví polia dokumentu uložené v indexe namiesto dokumentu.
- _zdroj – Booleovská hodnota, ktorá definuje, či má požiadavka vrátiť pole _source alebo nie.
Dotaz vyžaduje telo, ktoré obsahuje nasledujúce hodnoty:
- Docs – Určuje dokumenty, ktoré chcete načítať. Okrem toho táto časť podporuje nasledujúce atribúty:
- _id – Jedinečné ID cieľového dokumentu.
- _index – Index, ktorý obsahuje cieľový dokument.
- Smerovanie – Kľúč pre primárny zlomok dokumentu.
- _zdroj – Ak je pravda, zahŕňa všetky zdrojové polia; v opačnom prípade ich vylučuje.
- _stored_fields – Uložené_polia, ktoré chcete zahrnúť.
- ID – ID dokumentov, ktoré chcete načítať.
Príklad 1: Načítanie viacerých dokumentov z rovnakého indexu
Nasledujúci príklad ukazuje, ako použiť rozhranie Elasticsearch multi-get API na získanie dokumentov so špecifickými ID z indexu Netflix:
curl -XGET 'http://localhost:9200/netflix/_mget' -H 'kbn-xsrf: reporting' -H 'Content-Type: application/json' -d'{
'docs': [
{
'_id': 'T3wnVoMBck2AEzXPytlJ'
},
{
'_id': 'W3wnVoMBck2AEzXPytlJ'
}
]
}'
Daná požiadavka by mala načítať dokumenty so zadanými ID z indexu Netflix. Výsledný výstup je takýto:
{'docs': [
{
'_index': 'netflix',
'_id': 'T3wnVoMBck2AEzXPytlJ',
'_version': 1,
'_seq_no': 0,
'_primary_term': 1,
'nájdený': pravda,
'_source': {
'duration': '90 min',
'listed_in': 'Dokumentárne filmy',
'country': 'Spojené štáty',
'date_added': '25. september 2021',
'show_id': 's1',
'réžia': 'Kirsten Johnson',
'release_year': 2020,
'rating': 'PG-13',
'description': 'Keď sa jej otec blíži ku koncu života, filmárka Kirsten Johnson zinscenuje jeho smrť vynaliezavým a komickým spôsobom, aby im obom pomohla čeliť nevyhnutnému.',
'type': 'Film',
'title': 'Dick Johnson je mŕtvy'
}
},
{
'_index': 'netflix',
'_id': 'W3wnVoMBck2AEzXPytlJ',
'_version': 1,
'_seq_no': 12,
'_primary_term': 1,
'nájdený': pravda,
'_source': {
'country': 'Nemecko, Česká republika',
'show_id': 's13',
'riaditeľ': 'Christian Schwochow',
'release_year': 2021,
'rating': 'TV-MA',
'description': 'Po tom, čo je väčšina jej rodiny zavraždená pri teroristickom bombovom útoku, mladá žena je nevedomky nalákaná, aby sa pridala k tej istej skupine, ktorá ich zabila.',
'type': 'Film',
'title': 'Ja som Karl',
'duration': '127 min',
'listed_in': 'Drámy, medzinárodné filmy',
'cast': 'Luna Wedler, Jannis Niewöhner, Milan Peschel, Edin Hasanović, Anna Fialová, Marlon Boess, Victor Boccard, Fleur Geffrier, Aziz Dyab, Mélanie Fouché, Elizaveta Maximová',
'date_added': '23. september 2021'
}
}
]
}
Požiadavku môžeme tiež zjednodušiť vložením ID dokumentov do jednoduchého poľa, ako je uvedené nižšie:
curl -XGET 'http://localhost:9200/netflix/_mget' -H 'kbn-xsrf: reporting' -H 'Content-Type: application/json' -d'{
'ids': ['T3wnVoMBck2AEzXPytlJ', 'W3wnVoMBck2AEzXPytlJ']
}'
Predchádzajúca žiadosť by mala vykonať podobnú akciu.
Príklad 2: Získanie dokumentov z viacerých indexov
V nasledujúcom príklade požiadavka načíta viacero dokumentov z rôznych indexov, ako je znázornené:
curl -XGET 'http://localhost:9200/_mget' -H 'kbn-xsrf: reporting' -H 'Content-Type: application/json' -d'{
'docs': [
{
'_index': 'netflix',
'_id': 'T3wnVoMBck2AEzXPytlJ'
},
{
'_index': 'disney',
'_id': '8j4wWoMB1yF5VqfaKCE4'
}
]
}'
Výsledný výstup je takýto:

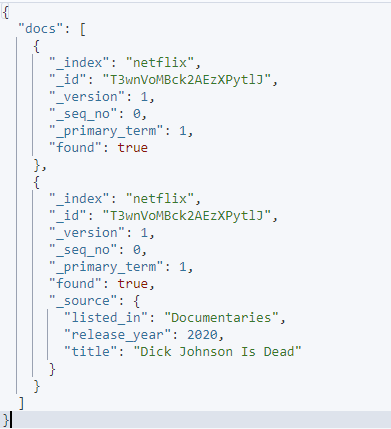
Príklad 3: Vylúčte špecifické polia
Z danej požiadavky môžeme vylúčiť konkrétne polia pomocou parametrov source_include a source_exclude.
Príklad je uvedený:
curl -XGET 'http://localhost:9200/_mget' -H 'kbn-xsrf: reporting' -H 'Content-Type: application/json' -d'{
'docs': [
{
'_index': 'netflix',
'_id': 'T3wnVoMBck2AEzXPytlJ',
'_source': nepravda
},
{
'_index': 'netflix',
'_id': 'T3wnVoMBck2AEzXPytlJ',
'_source': {
'include': [ 'listed_in', 'release_year', 'title' ],
'exclude': [ 'description', 'type', 'date_added' ]
}
}
]
}'
Daná požiadavka používa zdrojové zahrnutie a vylúčenie na určenie, ktoré polia chcete v danom dokumente získať.
Výsledný výstup je takýto:
Záver
V tomto príspevku sme diskutovali o základoch práce s rozhraním Elasticsearch multi-get API, ktoré vám umožňuje načítať viacero dokumentov z rôznych zdrojov na základe ich ID. Neváhajte a preskúmajte ďalšie dokumenty pre viac informácií.
Šťastné kódovanie!