Táto príručka ilustruje proces používania zhrnutia konverzácie v LangChain.
Ako používať zhrnutie konverzácie v LangChain?
LangChain poskytuje knižnice ako ConversationSummaryMemory, ktoré dokážu extrahovať úplný súhrn chatu alebo konverzácie. Môže sa použiť na získanie hlavných informácií o konverzácii bez toho, aby ste museli čítať všetky správy a texty dostupné v chate.
Ak sa chcete naučiť proces používania súhrnu konverzácie v LangChain, jednoducho prejdite na nasledujúce kroky:
Krok 1: Nainštalujte moduly
Najprv nainštalujte rámec LangChain, aby ste získali jeho závislosti alebo knižnice pomocou nasledujúceho kódu:
pip install langchain
Teraz nainštalujte moduly OpenAI po inštalácii LangChain pomocou príkazu pip:
pip install openai 
Po inštalácii modulov jednoducho nastaviť prostredie pomocou nasledujúceho kódu po získaní kľúča API z účtu OpenAI:
importovať vyimportovať getpass
vy . približne [ 'OPENAI_API_KEY' ] = getpass . getpass ( 'OpenAI API Key:' )
Krok 2: Použitie súhrnu konverzácie
Dostaňte sa do procesu používania súhrnu konverzácie importovaním knižníc z LangChain:
od langchain. Pamäť importovať Súhrn konverzáciíPamäť , ChatMessageHistoryod langchain. llms importovať OpenAI
Nakonfigurujte pamäť modelu pomocou metód ConversationSummaryMemory() a OpenAI() a uložte do nej údaje:
Pamäť = Súhrn konverzáciíPamäť ( llm = OpenAI ( teplota = 0 ) )Pamäť. save_context ( { 'vstup' : 'Ahoj' } , { 'výkon' : 'Ahoj' } )
Spustite pamäť zavolaním na load_memory_variables() metóda na extrahovanie údajov z pamäte:
Pamäť. load_memory_variables ( { } ) 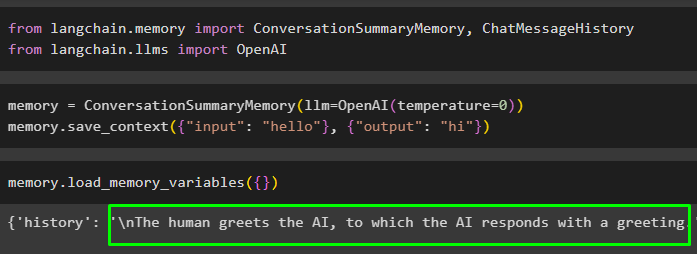
Používateľ môže tiež získať údaje vo forme konverzácie ako každá entita so samostatnou správou:
Pamäť = Súhrn konverzáciíPamäť ( llm = OpenAI ( teplota = 0 ) , návratové_správy = Pravda )Pamäť. save_context ( { 'vstup' : 'Ahoj' } , { 'výkon' : 'Ahoj, ako sa máš' } )
Ak chcete získať správu AI a ľudí oddelene, vykonajte metódu load_memory_variables():
Pamäť. load_memory_variables ( { } ) 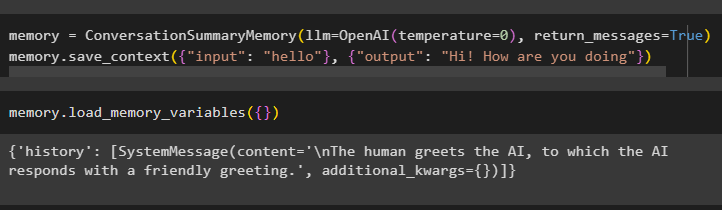
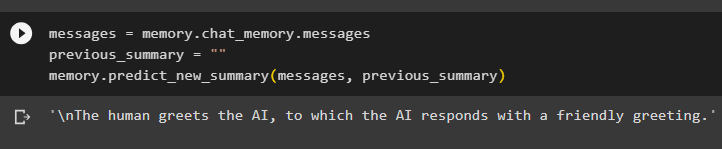
Uložte súhrn konverzácie do pamäte a potom spustite pamäť, aby sa na obrazovke zobrazil súhrn rozhovoru/konverzácie:
správy = Pamäť. chat_memory . správypredchádzajúci_zhrnutie = ''
Pamäť. predpovedať_nový_summary ( správy , predchádzajúci_zhrnutie )
Krok 3: Použitie súhrnu konverzácie s existujúcimi správami
Používateľ môže tiež získať súhrn konverzácie, ktorá existuje mimo triedy alebo chatu, pomocou správy ChatMessageHistory(). Tieto správy je možné pridať do pamäte, aby mohla automaticky vygenerovať súhrn celej konverzácie:
histórie = ChatMessageHistory ( )histórie. add_user_message ( 'Ahoj' )
histórie. add_ai_message ( 'Ahoj!' )
Zostavte model, ako je LLM, pomocou metódy OpenAI() na spustenie existujúcich správ v chat_memory premenná:
Pamäť = Súhrn konverzáciíPamäť. from_messages (llm = OpenAI ( teplota = 0 ) ,
chat_memory = histórie ,
návratové_správy = Pravda
)
Spustite pamäť pomocou vyrovnávacej pamäte, aby ste získali súhrn existujúcich správ:
Pamäť. vyrovnávacej pamäte 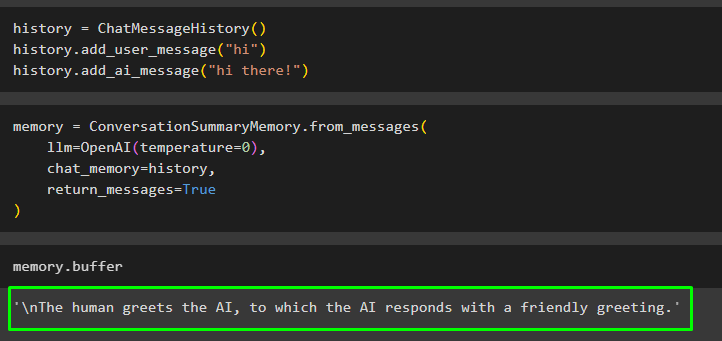
Vykonajte nasledujúci kód na vytvorenie LLM konfiguráciou vyrovnávacej pamäte pomocou správ chatu:
Pamäť = Súhrn konverzáciíPamäť (llm = OpenAI ( teplota = 0 ) ,
vyrovnávacej pamäte = '''Človek sa pýta stroja na seba
Systém odpovedá, že AI je vytvorená pre dobro, pretože môže pomôcť ľuďom dosiahnuť ich potenciál''' ,
chat_memory = histórie ,
návratové_správy = Pravda
)
Krok 4: Použitie súhrnu konverzácie v reťazci
Ďalší krok vysvetľuje proces používania súhrnu konverzácie v reťazci pomocou LLM:
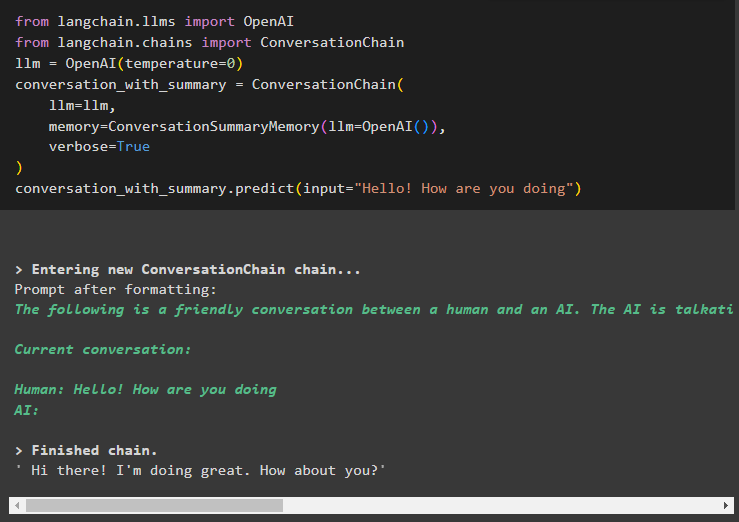
od langchain. llms importovať OpenAIod langchain. reťaze importovať ConversationChain
llm = OpenAI ( teplota = 0 )
rozhovor_so_zhrnutím = ConversationChain (
llm = llm ,
Pamäť = Súhrn konverzáciíPamäť ( llm = OpenAI ( ) ) ,
podrobný = Pravda
)
rozhovor_so_zhrnutím. predpovedať ( vstup = 'Ahoj ako sa máš' )
Tu sme začali budovať reťazce začatím konverzácie zdvorilým dotazom:
Teraz vstúpte do konverzácie tak, že sa opýtate trochu viac na posledný výstup, aby ste ho rozvinuli:
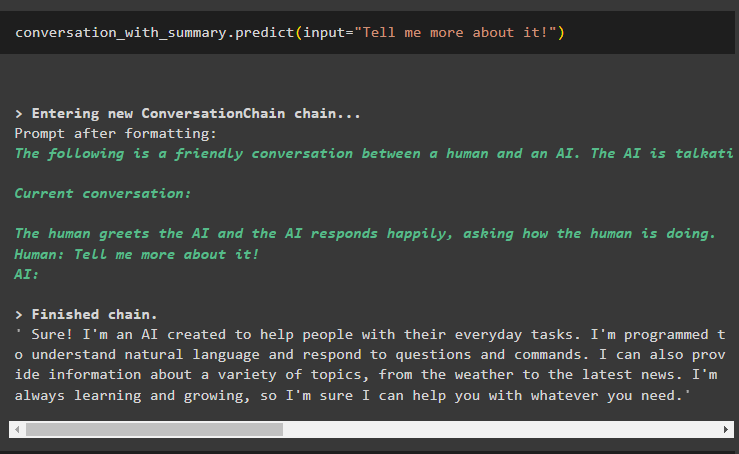
rozhovor_so_zhrnutím. predpovedať ( vstup = 'Povedz mi o tom viac!' )Model vysvetlil poslednú správu podrobným úvodom do technológie AI alebo chatbota:
Extrahujte bod záujmu z predchádzajúceho výstupu a nasmerujte konverzáciu konkrétnym smerom:
rozhovor_so_zhrnutím. predpovedať ( vstup = 'Úžasné, aký dobrý je tento projekt?' )Tu dostávame podrobné odpovede od robota pomocou knižnice súhrnnej pamäte konverzácie:
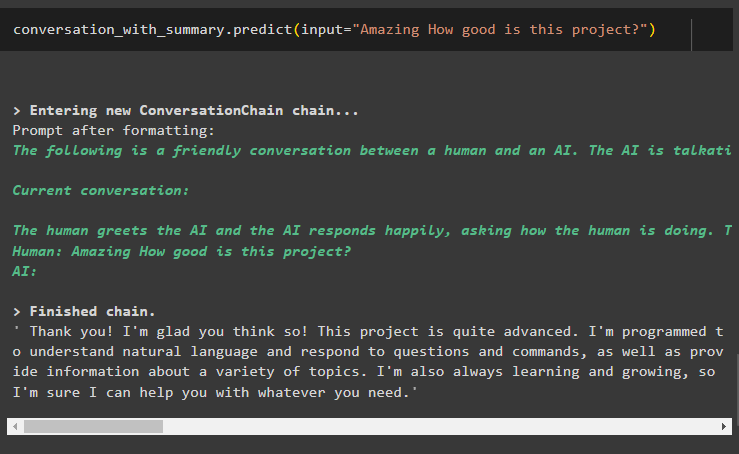
To je všetko o používaní súhrnu konverzácie v LangChain.
Záver
Ak chcete použiť súhrnnú správu konverzácie v LangChain, jednoducho nainštalujte moduly a rámce potrebné na nastavenie prostredia. Po nastavení prostredia importujte súbor Súhrn konverzáciíPamäť knižnice na vytváranie LLM pomocou metódy OpenAI(). Potom jednoducho použite súhrn konverzácie na extrahovanie podrobného výstupu z modelov, ktorý je zhrnutím predchádzajúcej konverzácie. Táto príručka rozpracovala proces používania pamäte súhrnu konverzácií pomocou modulu LangChain.