V tomto článku budeme diskutovať o tom, ako alokovať INÝ pamäť cez „ pytorch_cuda_alloc_conf “.
Čo je metóda „pytorch_cuda_alloc_conf“ v PyTorch?
V zásade platí, že „ pytorch_cuda_alloc_conf “ je premenná prostredia v rámci PyTorch. Táto premenná umožňuje efektívne riadenie dostupných zdrojov spracovania, čo znamená, že modely bežia a prinášajú výsledky v čo najmenšom možnom čase. Ak sa to neurobí správne, „ INÝ “výpočtová platforma zobrazí “ nedostatok pamäte ” a ovplyvní čas spustenia. Modely, ktoré sa majú trénovať pre veľké objemy údajov alebo majú veľké „ veľkosti dávok ” môže spôsobiť chyby pri spustení, pretože predvolené nastavenia na ne nemusia stačiť.
' pytorch_cuda_alloc_conf 'premenná používa nasledujúce' možnosti “ na spracovanie prideľovania zdrojov:
- natívny : Táto možnosť využíva už dostupné nastavenia v PyTorch na pridelenie pamäte prebiehajúcemu modelu.
- max_split_size_mb : Zabezpečuje, že žiadny blok kódu väčší ako špecifikovaná veľkosť nebude rozdelený. Ide o účinný nástroj na zabránenie „ fragmentácia “. Túto možnosť použijeme na demonštráciu v tomto článku.
- roundup_power2_divisions : Táto možnosť zaokrúhľuje veľkosť pridelenia na najbližší „ mocnosť 2 ” rozdelenie v megabajtoch (MB).
- roundup_bypass_threshold_mb: Môže zaokrúhliť veľkosť pridelenia nahor pre každú žiadosť, ktorá obsahuje viac ako špecifikovaný prah.
- garbage_collection_threshold : Zabraňuje latencii využívaním dostupnej pamäte z GPU v reálnom čase, aby sa zabezpečilo, že sa nespustí protokol reclaim-all.
Ako alokovať pamäť pomocou metódy „pytorch_cuda_alloc_conf“?
Každý model s veľkou množinou údajov vyžaduje dodatočné pridelenie pamäte, ktoré je väčšie ako predvolene nastavené. Vlastnú alokáciu je potrebné špecifikovať s ohľadom na požiadavky modelu a dostupné hardvérové zdroje.
Postupujte podľa krokov uvedených nižšie, aby ste použili „ pytorch_cuda_alloc_conf ” metóda v IDE Google Colab na pridelenie väčšej pamäte komplexnému modelu strojového učenia:
Krok 1: Otvorte Google Colab
Vyhľadajte Google Spolupracujúci v prehliadači a vytvorte „ Nový notebook “ začať pracovať:
Krok 2: Nastavte si vlastný model PyTorch
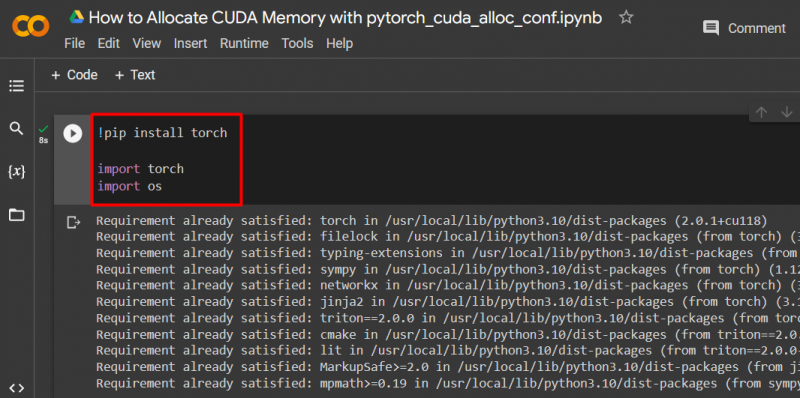
Nastavte model PyTorch pomocou „ !pip “ inštalačný balík na inštaláciu “ fakľa “knižnica a “ importovať “príkaz na import” fakľa “ a „ vy ” knižnice do projektu:
dovozová baterka
importujte nás
Pre tento projekt sú potrebné nasledujúce knižnice:
- Fakľa – Toto je základná knižnica, na ktorej je založený PyTorch.
- VY – „ operačný systém Knižnica sa používa na spracovanie úloh súvisiacich s premennými prostredia, ako napríklad pytorch_cuda_alloc_conf “, ako aj systémový adresár a oprávnenia súboru:
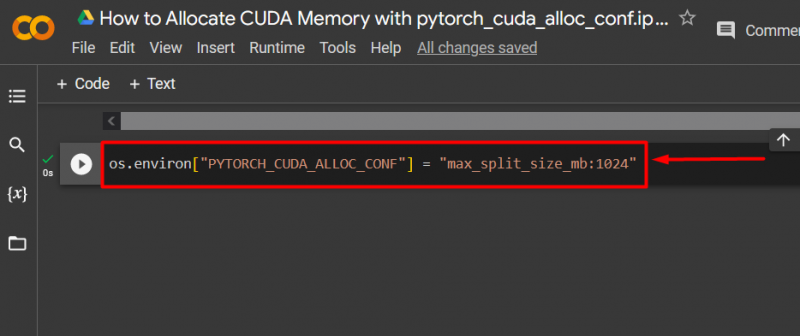
Krok 3: Prideľte pamäť CUDA
Použi ' pytorch_cuda_alloc_conf “ metóda na určenie maximálnej veľkosti rozdelenia pomocou “ max_split_size_mb “:
Krok 4: Pokračujte vo svojom projekte PyTorch
Po zadaní „ INÝ 'pridelenie priestoru pomocou ' max_split_size_mb “, pokračujte v práci na projekte PyTorch ako obvykle bez strachu z “ nedostatok pamäte ' chyba.
Poznámka : K nášmu zápisníku Google Colab môžete pristupovať tu odkaz .
Pro-Tip
Ako už bolo spomenuté, „ pytorch_cuda_alloc_conf “ môže mať ktorúkoľvek z vyššie uvedených možností. Použite ich podľa špecifických požiadaviek vašich projektov hlbokého učenia.
Úspech! Práve sme ukázali, ako používať „ pytorch_cuda_alloc_conf ” spôsob určenia “ max_split_size_mb “ pre projekt PyTorch.
Záver
Použi ' pytorch_cuda_alloc_conf ” metóda na pridelenie pamäte CUDA pomocou ktorejkoľvek z dostupných možností podľa požiadaviek modelu. Každá z týchto možností je určená na zmiernenie konkrétneho problému so spracovaním v rámci projektov PyTorch pre lepšie prevádzkové časy a plynulejšie operácie. V tomto článku sme predstavili syntax na použitie „ max_split_size_mb ” na definovanie maximálnej veľkosti rozdelenia.